Lorsque deux variables « varient » de concert, on peut affirmer qu’elles
sont reliées. Mais quelle est la nature réelle de leur relation? Est-ce
une relation de cause à effet? Autrement dit, est-ce que l’une des
variables (la variable dépendante) dépend de l’autre (la variable
indépendante) et si oui, laquelle, pourquoi et comment? Ou bien sommes-nous en présence d’une simple corrélation? Dans ce cas, se pourrait-il que les deux variables en jeu dépendent d’une troisième variable?
Au terme de ce chapitre, vous devriez être en mesure de répondre aux questions suivantes :
Comment, en examinant les chiffres, peut-on déceler s’il existe une relation entre deux variables?
Comment, lorsque les chiffres proviennent d’une enquête, peut-on déterminer si la relation observée peut être attribuable au hasard de l’échantillonnage?
Quelle est la nature de la relation? Est-ce une relation de cause à effet ou est-ce une simple corrélation?
Quelle est la force de la relation? Peut-on utiliser les résultats observés pour faire des prédictions intéressantes?
1. SCHÉMA DE RELATIONS
Qui influence quoi?
Avant de faire de savants calculs sur la force éventuelle d’une relation,
il est indispensable d’établir comment les variables sont reliées
les unes aux autres. Pour cela, rien ne vaut un bon vieux dessin. Nous vous
proposons ici deux procédés (schéma et courbe) permettant de clarifier
les relations entre les variables et de faire ressortir certains aspects
intéressants de ces relations.
1.1. Sagesse populaire
En Italie, une croyance populaire très ancienne veut que le vin soit
un fortifiant idéal pour un préadolescent un peu anémique. Un verre
quotidien, de rouge évidemment, et le sang retrouve ses couleurs.
Au pays de Descartes, cette coutume fait sourire. Au pays de Victoria,
elle scandalise. Enfin, au pays de Ti-Poil, on se contente de taxer
le vin sans juger personne. Et si la sagesse populaire italienne avait
raison envers et contre tous?
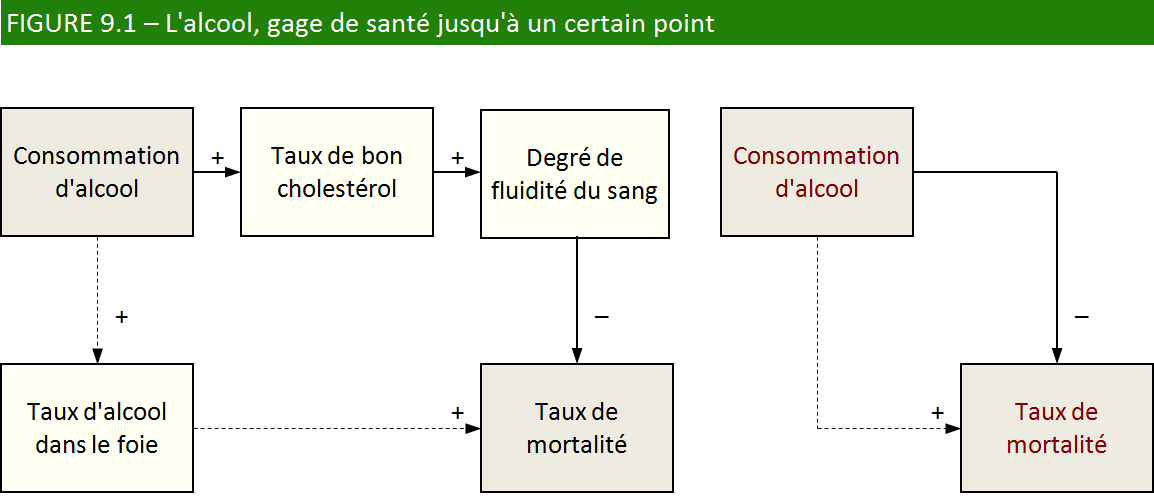
Qu’est-ce qui se cache derrière cette corrélation?
Selon une recherche citée par le magazine Sciences et Avenir de février 1995, on a observé une corrélation négative entre la consommation d’alcool et le taux de mortalité : corrélation parce que les deux variables varient en même temps, et négative parce qu’elles varient en sens inverse.
Il existe théoriquement trois manières de relier ces variables :
1) La consommation d’alcool (variable indépendante) exerce une influence sur le taux de mortalité (variable dépendante).
2) Le taux de mortalité (variable indépendante) exerce une influence sur la consommation d’alcool (variable dépendante).
3) La consommation d’alcool et le taux de mortalité sont toutes deux influencées par une troisième variable à découvrir.
La deuxième hypothèse doit être rejetée d’emblée parce qu’elle est absurde.
Par ailleurs, c’est grâce à la découverte des chaînons manquants reliant
les variables que nous pourrons finalement écarter la troisième hypothèse
et retenir la première. C’est ce que nous avons voulu illustrer dans
la figure 9.1.
Comment construire un schéma de variables.
Le schéma de variables, dont nous avons déjà vu quelques exemples
au chapitre 6, illustre les relations de cause à effet (représentées
par une flèche) entre les variables (représentées par des cases).
Les signes qui accompagnent les flèches représentent le sens de la
relation : un signe positif indique que les variables augmentent en
même temps et diminuent en même temps (relation directe); un
signe négatif indique que les variables varient en sens inverse.
Évidemment, le signe ne s’applique pas pour des variables purement
nominales dans lesquelles il n’y a ni ordre ni direction.
Dans le schéma, on constate qu’il y a une relation directe
entre la consommation d’alcool et le taux de bon cholestérol : les
deux variables varient dans le même sens, ce que nous indiquons par
un signe positif. On note aussi qu’il existe une relation inverse entre le degré de fluidité du sang et le taux de mortalité : lorsque le premier
augmente, le second diminue, ce que nous indiquons par un signe négatif.
Dans la partie droite de la figure 9.1, nous avons fait la synthèse
de la relation en éliminant toutes les variables intermédiaires : la
cause (consommation d’alcool) est reliée à l’effet (taux de mortalité)
par une flèche surmontée d’un signe négatif. Ce signe est obtenu en
combinant tous les signes successifs du schéma original, en prenant
pour principe que la relation change de sens chaque fois que l’on
rencontre un chiffre négatif.
Alors, vite! Une bouteille et ça presse? Minute! Il est clair que
nous nous sommes contentés d’étudier un seul aspect de la question.
Passé un certain seuil, par exemple, la consommation d’alcool est
reliée de façon inverse au taux de mortalité par l’intermédiaire
de ce cher vieux foie que nous avons tous.
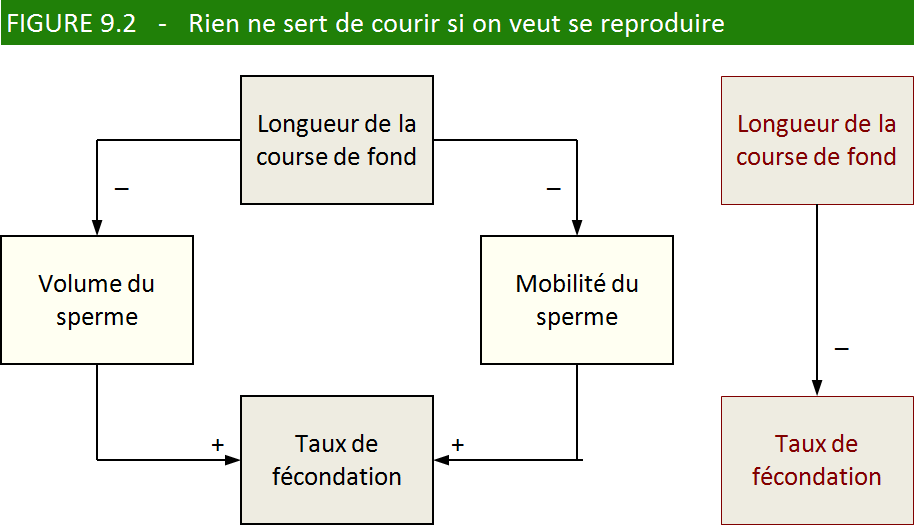
1.2. Tarzan au lit
Rien de tel qu’épouser une personne bardée de prix Nobel ou de médailles
olympiques pour avoir des enfants beaux et forts, n’est-ce pas? Cependant,
avant de faire votre demande en mariage, prenez note du fait suivant :
on a observé, chez les hommes qui s’adonnent à la course de fond,
que le sperme était moins volumineux et les spermatozoïdes moins mobiles
que d’ordinaire. De quoi diminuer les chances de fécondation? On serait
tenté de prétendre que le faible volume de sperme réduit la mobilité
des spermatozoïdes, un peu à la manière des billots qui se traînent
misérablement sur une rivière l’été. Il n’en est rien cependant. Les
phénomènes sont seulement corrélés, car ils dépendent d’une variable
commune : la longueur de la course de fond, et l’état d’épuisement
qui en résulte. C’est très sérieux! Nous l’avons également appris dans la revue
Sciences et Avenir (voir le schéma de la figure 9.2).
1.3. L’alcool au volant
Cette fois, l’alcool est plutôt nuisible.
Vous avez un ami qui a déjà conduit en état d’ivresse sans avoir d’accident.
Cet ami en déduit que l’alcool et le volant font bon ménage, d’autant
plus que son oncle, antialcoolique notoire, a déjà provoqué un carambolage
monstre sur l’autoroute métropolitaine après avoir bu un verre d’eau.
Il n’en demeure pas moins que les conducteurs qui ont une prédilection
pour la dive bouteille ont beaucoup plus de chance d’être impliqués
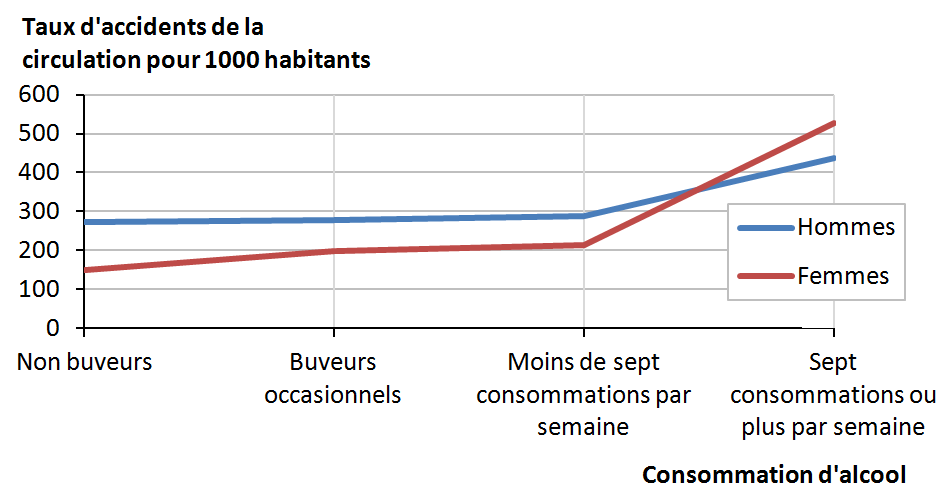
dans un accident de la route que les non-buveurs. C’est ce qu’indique l’étude
menée par Statistique Canada (voir la figure 9.3). Si un dessin vaut
mille mots, une courbe vaut parfois mille calculs : nous avons tracé,
sous la figure 9.3, des courbes* qui mettent en évidence la relation entre consommation d’alcool (sur l’axe horizontal) et taux
d’accident (sur l’axe vertical).
Comment interpréter les différences entre hommes et femmes? Une fausse
explication serait de dire que les femmes boivent moins que les hommes.
Que cela soit vrai ou non, cela n’a pas d’influence ici puisqu’on
nous donne des taux d’accidents par catégorie de buveurs, et non des
fréquences brutes. Il se pourrait également que les femmes conduisent
mieux que les hommes — sauf celles qui boivent le plus. Cette hypothèse
n’est pas à rejeter, quoiqu’il soit facile de proposer une autre explication :
il se peut que les femmes aient moins d’accidents parce qu’elles
conduisent moins. Il ne reste plus qu’à trouver les chiffres qui permettent
de confirmer ou de rejeter toutes ces hypothèses.
1.4. La télévision
Si la durée d’écoute hebdomadaire de la télévision est très élevée
au Québec, elle commence néanmoins à décliner. Les méchantes langues
diront que c’est parce que de nouvelles formes d’abrutissement ont
été mises au point. Au fait, savez-vous qui regarde le plus la télévision :
les hommes ou les femmes? Les « vrais » Québécois ou les « faux »? Encore
une fois, des chiffres bien choisis vont pouvoir détruire (ou renforcer)
quelques préjugés.
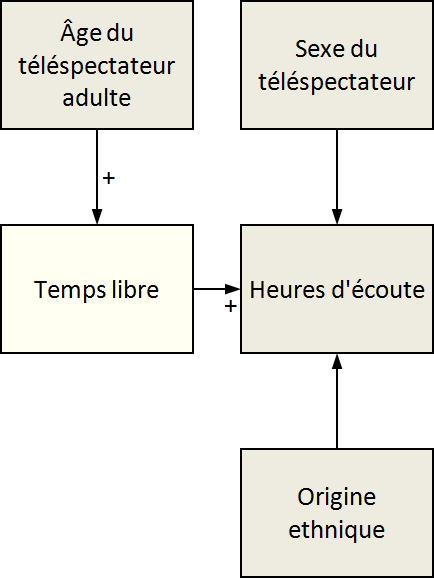
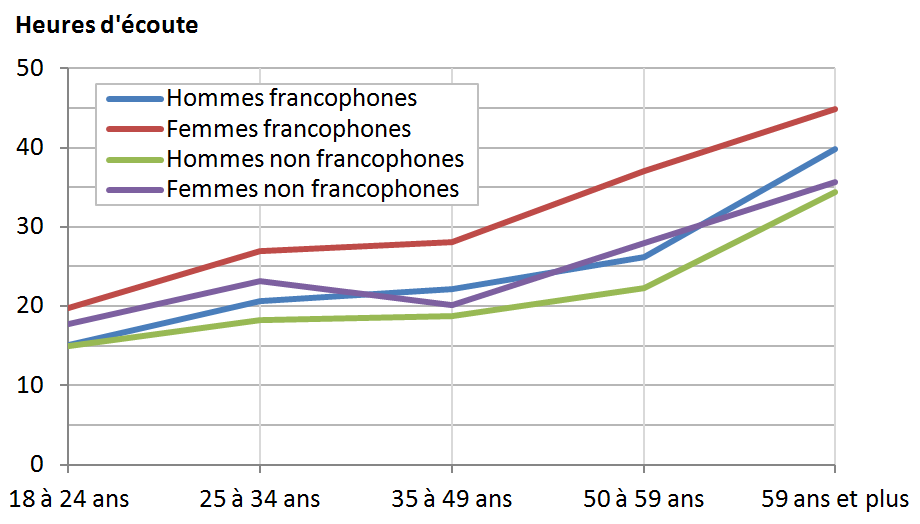
Dans la figure 9.4, nous avons choisi
de représenter par des courbes la relation entre heures d’écoute
(sur l’axe vertical, la position préférée de la variable dépendante) et groupe d’âge (sur l’axe horizontal*. Les
courbes mettent bien en évidence le fait que l’écoute de la télévision
augmente avec l’âge. Cela dit, la véritable explication vient peut-être
du fait que les vieux ont plus de temps libre que les jeunes (voir
le schéma de variables au centre de la figure 9.4). Pour vérifier cette hypothèse,
on pourrait consulter une des nombreuses études sur le temps libre*. Cette influence de l’âge sur les heures d’écoute se retrouve
systématiquement chez les deux sexes et auprès des deux groupes ethniques.
Encore une fois, l’utilisation de courbes et d’un schéma de variables
a permis de mettre en évidence la relation et d’enrichir la description
du phénomène.
1.5. Un cas plus complexe : les deux variables s’influencent mutuellement
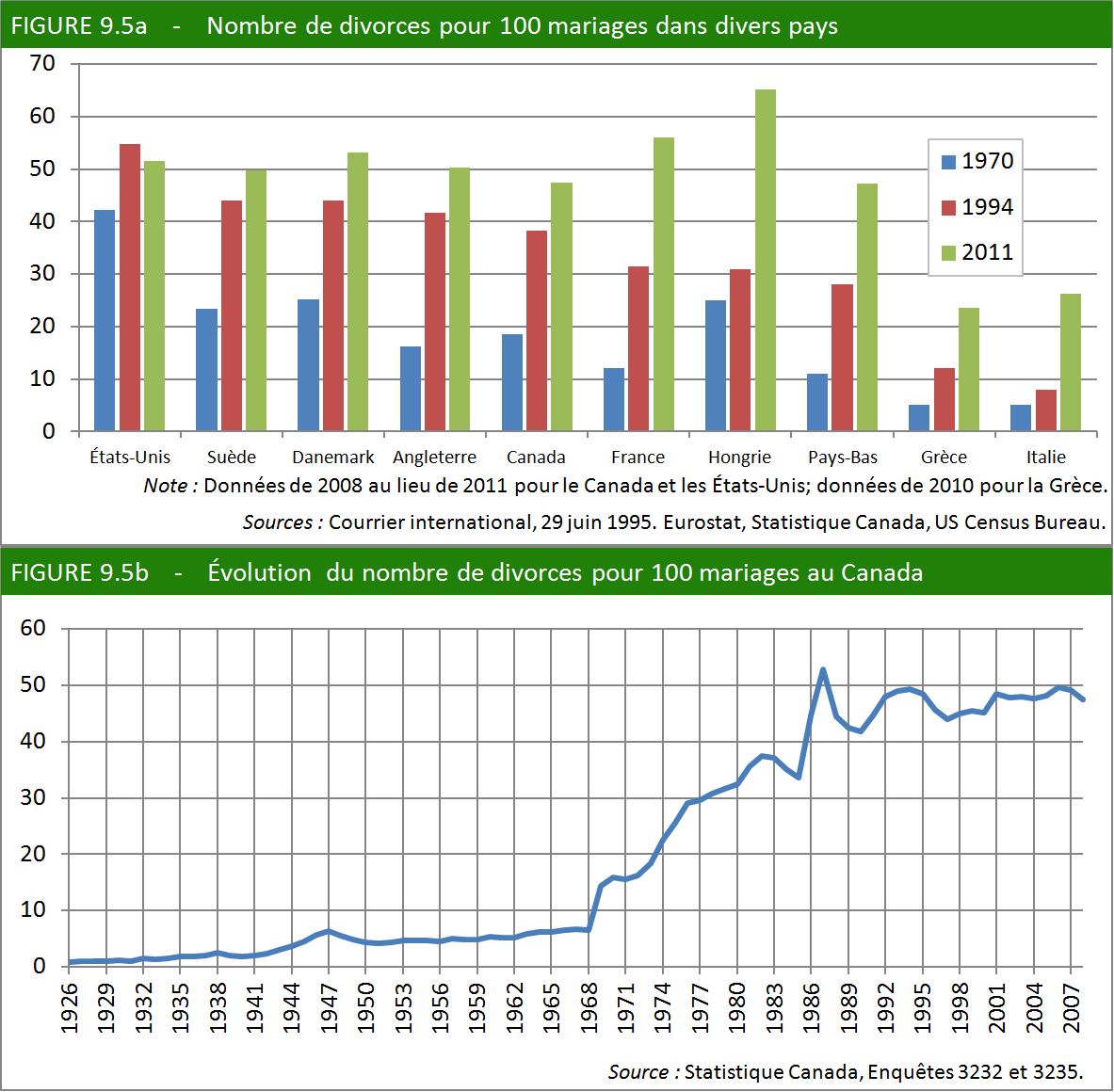
Le taux de divorce, c’est-à-dire le nombre de divorces par rapport au nombre de mariages,
est en hausse dans tous les pays industrialisés. En observant la figure
9.5, on se demande si le divorce et le développement économique ne
sont pas corrélés.
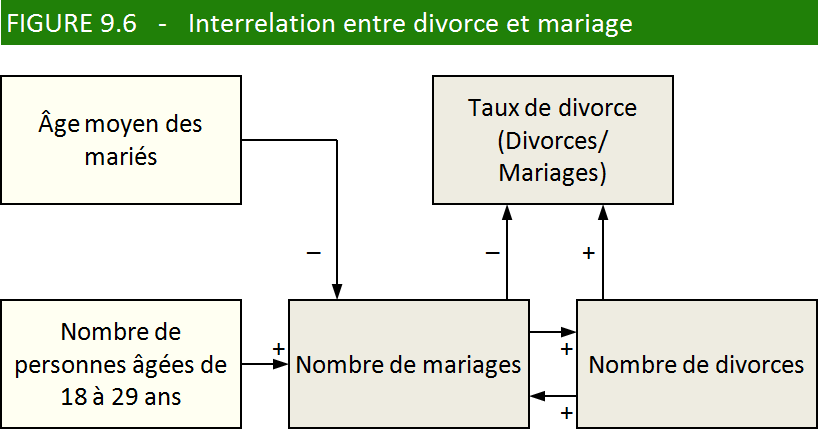
Nous utiliserons ce dernier exemple pour montrer qu’il n’est pas toujours
facile de distinguer la variable dépendante de la variable indépendante
dans une relation de cause à effet. Le nombre de divorces dépend,
entre autres, du nombre de mariages : seuls les gens mariés peuvent
divorcer. Mais le nombre de divorces peut, lui aussi, influencer le
nombre de mariages : chaque divorcé est un futur marié potentiel remis
« sur le marché ». Nous avons illustré cette influence réciproque à
la figure 9.6, que nous avons par ailleurs enrichie en tenant compte
de certains facteurs démographiques : lorsqu’une vague de jeunes arrive
à l’âge de convoler, le nombre de mariages augmente naturellement,
suivi, quelques années plus tard par une hausse du nombre de divorces.
EXERCICES 1
1. Le thé, autre gage de santé
Répondez aux questions en vous référant au schéma de variable de la figure 9.7.
a) Quelle est la nature de la relation entre la consommation de thé
vert et l’incidence du cancer de l’œsophage (simple corrélation ou
relation de cause à effet)?
b) Si la relation en est une de cause à effet, quelle est la variable
associée à la cause, quelle est la variable associée à l’effet et
quel est le sens de la relation (direct ou inverse)?
2. Quand on n’en a pas on l’aime, quand on en a on s’ennuie
a) Pour mettre en évidence la relation entre l’âge et l’organisation du temps des individus, tracez des courbes, à partir des données du tableau 9.1.
b) À propos de la figure 9.4, nous avions émis une hypothèse selon laquelle les personnes plus âgées ont de bonnes raisons
d’écouter la télévision, étant donné qu’elles disposent de plus de temps libre que les jeunes.
Le tableau 9.1 confirme-t-il cette hypothèse?
2. RELATION ENTRE DEUX VARIABLES QUALITATIVES
Après avoir constaté la présence d’une relation entre deux variables,
il reste à évaluer la force de cette relation. Par ailleurs, si les
chiffres obtenus proviennent d’un simple échantillon, il faut prendre
quelques précautions supplémentaires en s’assurant que les résultats
observés ne sont pas l’effet du hasard.
2.1. Le tableau croisé
Chaque colonne du tableau croisé correspond à une catégorie
d’une des deux variables et chaque ligne correspond à une catégorie
de l’autre variable.
Lorsque les variables sont qualitatives, on a souvent recours à un
croisement entre les catégories de chaque variable*. Dans
le cas du tabagisme chez les jeunes, par exemple, on pourrait croiser
la variable sexe (en colonnes) avec la variable consommation
de cigarettes (en lignes) pour déterminer si le sexe a une influence
sur le comportement (l’inverse est peu probable!). Chaque case du
tableau croisé contiendra une fréquence, c’est-à-dire le nombre
d’individus correspondant simultanément à la caractéristique de la
colonne et à celle de la ligne.
Dans chaque case du tableau croisé, on inscrit les fréquences
associées à la catégorie de la colonne et à celle de la ligne correspondantes.
Les données du tableau 9.2 et du tableau 9.3 proviennent
de deux enquêtes effectuées dans les années 1990 sur les adolescents
au Québec. Nous les avons extraites d’un article publié dans la Revue
québécoise de psychologie dans lequel l’auteur cherche à montrer
que la perception des gens à l’égard des adolescents est plus influencée
par les préjugés que par la réalité. Notre propos est ici beaucoup
plus modeste : nous utiliserons deux exemples de cette recherche pour
étudier la présence et la force d’une relation entre deux variables
qualitatives. Le premier exemple traite d’un comportement (« fumes-tu
la cigarette? ») et le second d’une perception des choses (« mes parents
se chicanent souvent entre eux »). Nous essaierons de déterminer si
le sexe a une influence sur le comportement (dans le premier cas)
ou sur les perceptions (dans le second).
Commençons par observer les données brutes de l’enquête sur le tabagisme.
Dans le tableau 9.2a, on constate que 5580 élèves du secondaire
ont été interrogés, dont 2650 garçons et 2930 filles. Sur les 2930
filles interrogées, 322 déclarent fumer régulièrement, 355 à l’occasion
et 2253 jamais. Toutes proportions gardées, puisque l’échantillon
contient davantage de filles que de garçons, ces dernières semblent plus
enclines à fumer que leurs confrères.
Pour en avoir le cœur net, observons les proportions calculées dans
le tableau 9.2b. Étant donné que les filles représentent 52,5 %
de l’échantillon, on peut s’attendre à retrouver dans la colonne « filles »
des proportions légèrement supérieures à celles de la colonne « garçons ».
Or, on constate que sur les 9,3 % d’élèves qui fument régulièrement,
5,8 % sont des filles et 3,5 % sont des garçons : on ne peut plus parler
de « légères » différences.
Étant donné que 9,3 % des élèves fument régulièrement et que 47,5
% d’entre eux sont des garçons, on pourrait s’attendre à ce que 9,3
% x 47,5 % des fumeurs réguliers soient des garçons. Sur les 5580
élèves interrogés, il devrait donc y avoir « théoriquement » 9,3 % x
47,5 % x 5580 = 246 garçons classés comme fumeurs réguliers. C’est
ce qu’on appelle la fréquence théorique (tableau 9.2c), par opposition
à la fréquence observée (tableau 9.2a).
Fréquence théorique d’une case = Proportion de la ligne x Proportion de la colonne x Fréquence totale
Fréquence théorique de filles qui ne fument jamais = 80,5 % x 52,5 % x 5580 = 2358
(Ou encore : 0,805 x 0,525 x 5580 = 2358)
Si le sexe n’exerçait aucune influence sur le tabagisme, la répartition
des élèves entre les diverses catégories (tableau 9.2a) devrait ressembler
à celle obtenue dans le tableau des fréquences théoriques (tableau 9.2c). Lorsque l’on compare ces fréquences théoriques aux fréquences
observées dans l’enquête, on constate toutefois certains écarts, qui
ne sont ni énormes ni négligeables. L’utilisation d’un outil assez
répandu, le Khi carré, va nous permettre d’évaluer l’importance de
cet écart et de l’interpréter.
Examinons la première case du tableau 9.2a : 196 individus y sont recensés alors qu’on s’attendait à en retrouver 246 (voir tableau 9.2c). On
est donc en déficit de 50 individus (–50) sur un total de 246. Comme
c’est l’écart absolu qui est important, nous nous débarrassons du signe
en mettant cet écart au carré avant de le diviser par le total. Nous obtenons ainsi l’écart au carré relatif.
Écart² relatif pour les garçons qui fument régulièrement = (196 – 246)²/246 = 2500/246 = 10,16
On retrouve ce dernier chiffre dans le tableau 9.2d. Le Khi carré
n’est autre que la somme de tous ces écarts : il est ici de 50,08.
Si les fréquences observées correspondaient exactement aux fréquences
théoriques, le Khi carré aurait une valeur de 0. Il nous faut maintenant
interpréter la valeur de 50,08 que nous avons obtenue.
2.2. L’écart peut-il être attribué au hasard?
Les données que nous venons d’utiliser proviennent d’une enquête.
Faute d’information précise sur la population des élèves du secondaire
dans son ensemble, nous devons nous contenter d’un échantillon. Mais
quelles sont les chances que nous soyons tombés, par malheur, sur
un échantillon non représentatif? Comme pour le test d’hypothèse (vu
au chapitre précédent), nous allons nous donner un seuil de signification,
mettons 0,05 (ou 5 %, ou 1/20). Cela signifie que nous ne voulons courir
le risque de nous tromper qu’une fois sur 20 si jamais nous émettons
l’hypothèse selon laquelle les écarts sont suffisamment grands pour ne pas être
le simple effet du hasard*.
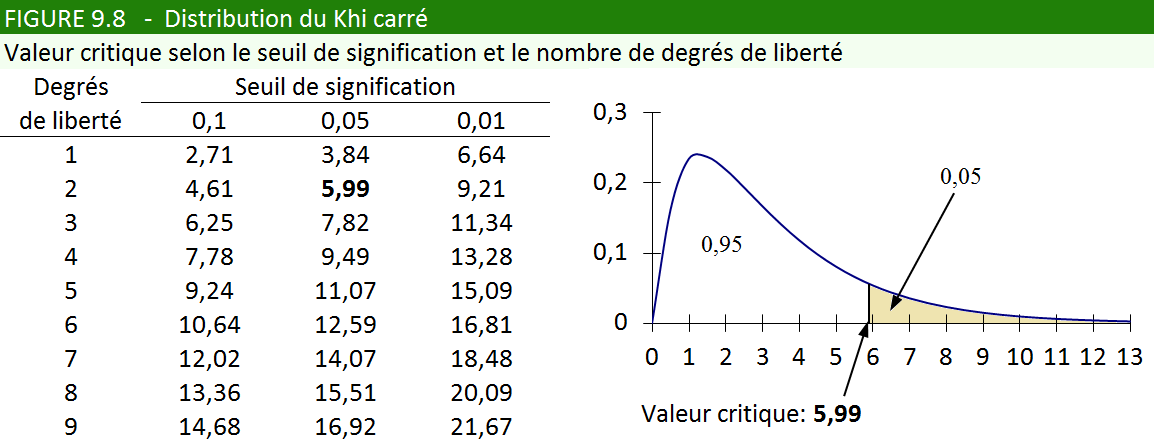
La figure 9.8 nous indique la valeur critique, c’est-à-dire la valeur
minimale que doit atteindre notre Khi carré pour que nous puissions
accepter notre hypothèse avec un risque de nous tromper inférieur
à 5 %. Mais comme le Khi carré est influencé par la taille du tableau
(plus le tableau est grand, plus les écarts s’accumulent), il nous
faut tenir compte du nombre de colonnes et lignes du tableau. C’est
ce qu’on appelle le nombre de degrés de liberté.
Degrés de liberté = (Nombre de colonnes – 1) x (Nombre de lignes – 1)
Degrés de liberté = (2 – 1) x (3 – 1) = 1 x 2 = 2
Dans la table de distribution du Khi carré, la valeur correspondant à un seuil de signification de 0,05 et à 2 degrés de liberté est égale à 5,99. Or, l’écart que nous avons calculé (50,08) dépasse largement cette valeur critique. En fait, nous sommes si loin au-dessus de la
valeur critique qu’il est pratiquement impossible que les écarts
constatés soient imputables à un hasard d’échantillonnage. Cette certitude
n’est pas étrangère au fait que nous disposons d’un échantillon très
élevé : la loi des grands nombres joue encore en notre faveur. Autrement
dit, le Khi carré a d’autant plus de chances d’être élevé que l’échantillon
est grand.
Le nombre de degrés de liberté peut s’interpréter de la façon suivante : nous avons sous la main un tableau dans lequel on croise les deux catégories d’une première variable (le sexe) avec les trois catégories d’une seconde variable (le tabagisme). Il va de soi que les totaux rajoutés aux lignes et aux rangées du tableau sont déterminés d’avance et ne relèvent en rien du hasard. Or, une fois que l’on connaît les fréquences associées aux garçons, par exemple, on peut en déduire automatiquement les fréquences des filles. De la même façon, une fois connues les fréquences des deux premières catégories concernant le tabagisme, nous connaissons également la fréquence de la troisième catégorie. En somme, la dernière colonne et la dernière ligne du tableau (totaux exclus) sont prédéterminées par les autres colonnes et lignes. C’est pourquoi on les exclut dans le calcul du nombre de degrés de liberté.
2.3. La relation est-elle forte?
Si nous venons d’éviter une première embûche, il nous faut maintenant
évaluer dans quelle mesure la relation observée est forte. Nous pouvons affirmer que les filles sont plus portées à fumer que
les garçons. Mais cela est-il suffisant, par exemple, pour nous permettre
de prédire facilement, à partir de son sexe, si un élève fume?
Si nous avions croisé le sexe des élèves avec une autre variable,
comme le port du soutien-gorge ou de la coquille protectrice dans
les arts martiaux, nous aurions sûrement eu des écarts encore plus
tranchés. Notre Khi carré aurait été suffisamment élevé pour que nous
puissions déduire à partir de ses habitudes vestimentaires, et sans
grand risque de nous tromper, si un budōka est une fille ou un garçon.
Un des instruments les plus courants pour évaluer la force de la relation
entre deux variables qualitatives est le V de Cramer. On comprendra
que le Khi carré ne peut tout dire à lui tout seul, puisqu’il dépend
en partie de la taille de l’échantillon. Le V de Cramer tient compte
de cet aspect. Notez, en observant la formule ci-après, que vous auriez
pu facilement inventer vous-même un coefficient correspondant et passer
ainsi à la postérité.
où n représente la taille de l’échantillon et K le nombre minimal de rangées et de colonnes.
On compte 3 rangées et 2 colonnes dans le tableau 9.2. C’est le plus petit de ces deux chiffres que l’on retient pour calculer le V de Cramer.
V de Cramer = √[50,08/5580 x (2–1)] = 0,095
S’il n’y avait aucune relation entre les deux variables, le V de Cramer
serait égal à 0, tout comme le Khi carré. Si la relation était parfaitement
tranchée (par exemple si toutes les filles fumaient et si tous les
garçons ne fumaient pas), le V de Cramer serait égal à 1. Dans le
cas du port du soutien-gorge ou de la coquille protectrice, on aurait
peut-être un V de Cramer égal à 0,99<$F>. En général, on considère que l’association entre les
variables commence à être intéressante à partir de 0,10, forte à partir
de 0,40 et robuste à partir de 0,70, mais cela dépend du contexte.
Ici, nous avons un coefficient relativement faible (0,095). Il y a
certes une différence de comportement entre les garçons et les filles,
mais cette différence est trop faible pour qu’on puisse prédire, à
partir de son sexe, si un élève fume. Dans les paragraphes qui suivent, nous proposerons deux exemples de conclusions
que l’on pourrait tirer à la lecture de ce chiffre : la première est
acceptable et la seconde, abusive.
Une conclusion honnête
Il est clair que les écolières fument un peu plus que les garçons.
Pour mieux comprendre la situation, nous pourrions nous poser diverses
questions : « Pourquoi telle fille fume-t-elle? Pourquoi telle autre ne fume-t-elle pas? Qu’est-ce qui pousse un jeune à fumer? Qu’est-ce qui pousse un
garçon à fumer? », etc.
Une conclusion biaisée
« Puisque les filles fument plus que les garçons, je refuse d’embaucher
des filles dans mon usine de dynamite. » Cette affirmation serait aussi
ridicule que les suivantes : « Puisque les faux-monnayeurs sont plus
souvent des étrangers (V de Cramer à l’appui), un commerçant ne devrait
pas accepter les billets de ses clients italiens » ou encore « Puisqu’une
proportion relativement grande d’Asiatiques ont un QI supérieur à
100, les universités de devraient pas engager de professeurs originaires
d’Europe. »
2.4. Mes parents se chicanent, un peu, beaucoup
Les données du tableau 9.3 proviennent d’une enquête effectuée
auprès d’un échantillon de 3180 élèves du secondaire du Québec âgés
de 11 à 19 ans. L’échantillon initial comptait 6121 élèves choisis
au hasard, mais 2916 questionnaires ne furent pas remplis et 25 questionnaires
furent rejetés. Certaines des questions portaient sur la violence
verbale et physique au sein de la famille. On demandait notamment
à l’élève d’évaluer si ses parents se chicanaient souvent entre eux,
à partir de l’échelle ordinale suivante : 1. Correspond tout à fait
à ce que je vis; 2. Correspond un peu à ce que je vis; 3. Ne correspond
pas vraiment à ce que je vis; 4. Ne correspond pas du tout à ce que
je vis.
Sur les 3130 élèves qui ont été en mesure de répondre à cette question précise,
les filles semblent relativement plus nombreuses à estimer que leurs
parents se chicanent. Étant donné que les garçons et les filles partagent
généralement les mêmes parents, on peut considérer que les réponses
reflètent non seulement la réalité, mais également la perception
de cette réalité. Par ailleurs, il faut noter que la plupart des parents
sont bel et bien des adeptes de la coexistence pacifique.
Des calculs similaires à ceux effectués pour le tableau 9.2 nous montrent
que le Khi carré est égal à 19,27. Ce tableau contient cependant plus
de cases que le précédent : on y compte 2 colonnes et 4 lignes, soit (2 – 1) × (4 – 1 ) = 1 × 3 = 3 degrés de liberté. Si l’on prend ici encore
un seuil de signification de 0,05, la valeur critique est de 7,82
(revoir la figure 9.8). Notre Khi carré est donc suffisamment grand
pour qu’on ne puisse pas mettre les différences observées entre garçons
et filles sur le dos du hasard.
Encore une fois, le V de Cramer est relativement petit : √[19,27/3130 × (2 – 1)] = 0,08. L’association entre le sexe et la perception
de la réalité est donc plutôt faible. Même si la relation existe,
il serait présomptueux de formuler des généralisations.
EXERCICES 2
1. Des jeunes drogués
a) Vérifiez dans le tableau 9.2 la proportion, la fréquence théorique
et l’écart pour les filles qui fument régulièrement.
b) Quelle aurait été la valeur critique du Khi carré si nous avions
choisi un seuil de signification de 0,01 pour le tableau 9.2? Commentez.
2. Une jeunesse qui s’envole en fumée
Le tableau 9.4 contient des informations similaires à celles du tableau 9.2. Les données sont cependant tirées d’une enquête différente et portent sur une période plus récente.
a) Construisez un tableau contenant les proportions pour chaque case.
b) Construisez un tableau contenant les fréquences théoriques pour
chaque case.
c) Construisez un tableau contenant les écarts au carré relatifs.
d) Calculez le Khi carré. Comparez à la valeur critique dans le tableau
de distribution du Khi carré pour un seuil de signification de votre
choix.
e) Calculez le V de Cramer.
f) Comparez les résultats obtenus à ceux du tableau 9.2. Commentez.
3. RELATION ENTRE DEUX VARIABLES QUANTITATIVES
Comme nous venons de le voir, le tableau croisé est un outil privilégié
pour observer une relation entre deux variables qualitatives. Lorsque
les deux variables sont quantitatives, on doit avoir recours à un
autre procédé : la corrélation. La situation suivante expliquera de
quoi il en retourne.
3.1. La corrélation
On dit souvent qu’il y a des chômeurs instruits. Même si cela est
vrai, il s’agit néanmoins d’une espèce relativement rare si on la
compare à celle des chômeurs « ignorants ». Supposons que le taux de
chômage soit en moyenne de 2 % pour une personne qui détient un doctorat
(7 ans d’études universitaires), de 6 % pour une personne qui détient
une maîtrise (5 ans d’études universitaires) et de 10 % pour une personne
qui détient un baccalauréat (3 ans d’études universitaires). Si la
tendance se maintient, comme on dit, il est probable que le taux de
chômage soit de 16 % pour une personne qui a interrompu ses études
juste avant de rentrer à l’université. On pourrait même construire
une formule qui permette de prédire le taux de chômage associé à un
nombre x d’années d’études universitaires : Puisqu’il semble que chaque
année d’étude fasse baisser le chômage de 2 points de pourcentage,
la formule du taux de chômage serait donc la suivante :
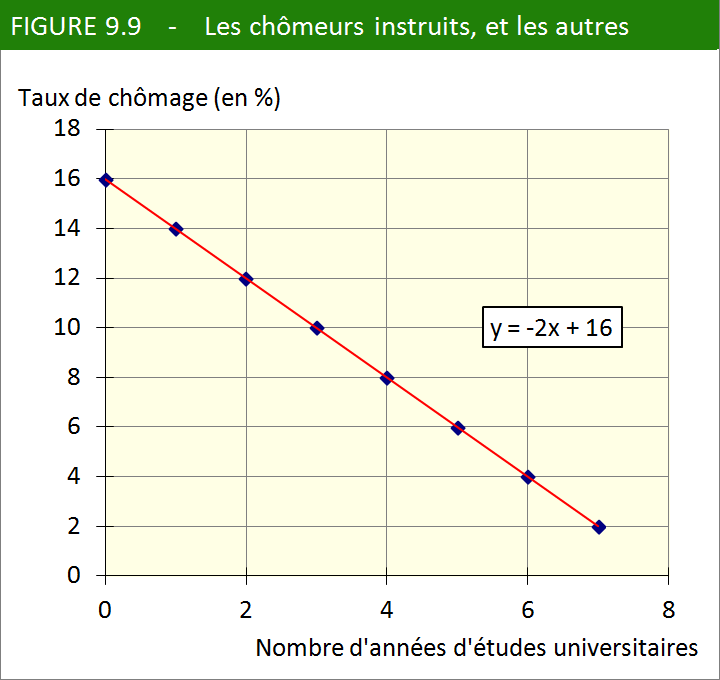
y = 16 – 2x
Lorsque des points, représentant la valeur d’une variable par
rapport à une autre variable, sont plus ou moins alignés, la droite de régression est celle qui s’éloigne le moins possible de l’ensemble
des points.
Dans cette équation, y représente (en points de pourcentage) le taux
de chômage, et x, le nombre d’années d’études universitaires. Après
4 années d’études universitaires, le taux de chômage serait, selon
notre formule, de 16 – 2 × 4 = 8 points de pourcentage. L’équation peut
également être représentée sous forme de courbe (ou droite de régression) comme dans la figure 9.9.
Il y a corrélation entre deux variables lorsque ces deux variables se suivent de façon plus ou moins systématique, que ce soit dans le même sens ou en sens inverse.
Dans l’exemple que nous venons de présenter, on peut dire qu’il existe
une corrélation parfaite entre les deux variables : le niveau
universitaire atteint et le taux de chômage. Évidemment, la réalité
humaine n’est pas aussi simple, et de toute façon, on ne peut pas
tirer de grandes conclusions d’un échantillon aussi petit. Il existe
cependant de nombreuses situations reliées aux sciences humaines dans lesquelles
il est possible de tracer une droite de régression mettant en relation
deux variables x et y. Il s’agit alors de déterminer la valeur des
paramètres qui caractérisent l’équation de cette droite. Ces deux
paramètres sont ici les nombres 16 et –2. On cherchera alors à évaluer
dans quelle mesure les faits observés coïncident avec la droite tracée.
Le coefficient de corrélation mesure la force de la corrélation entre deux variables.
Plus généralement, on écrit l’équation de la droite sous la forme :
y = a + bx, dans laquelle a est l’ordonnée à l’origine et b la pente.
Une fois qu’on a déterminé la valeur de a et de b, on devrait être
capable, connaissant x, de trouver y avec un certain degré de fiabilité
(mesuré par le coefficient de corrélation). C’est ce que nous
allons faire avec des données internationales.
3.2. Qui s’instruit… vit plus longtemps?
Nous avons choisi d’étudier la corrélation éventuelle entre l’éducation
et la santé des gens. Plus précisément, nous avons retenu deux variables
facilement observables à travers le monde : le taux d’analphabétisme
des adultes et l’espérance de vie à la naissance. Pour ne pas encombrer
le tableau, nous n’avons sélectionné que les gros pays (peuplés de
50 millions et plus) pour lesquels les données existent. Nous avons
exclu de l’échantillon les pays industrialisés pour lesquels les
taux officiels d’analphabétismes sont égaux à zéro. Grâce à ces simplifications,
peut-être excessives, il nous sera plus facile de montrer comment
construire et interpréter la droite de régression. En fin de compte,
nous avons retenu 13 pays et nous avons représenté les données sous
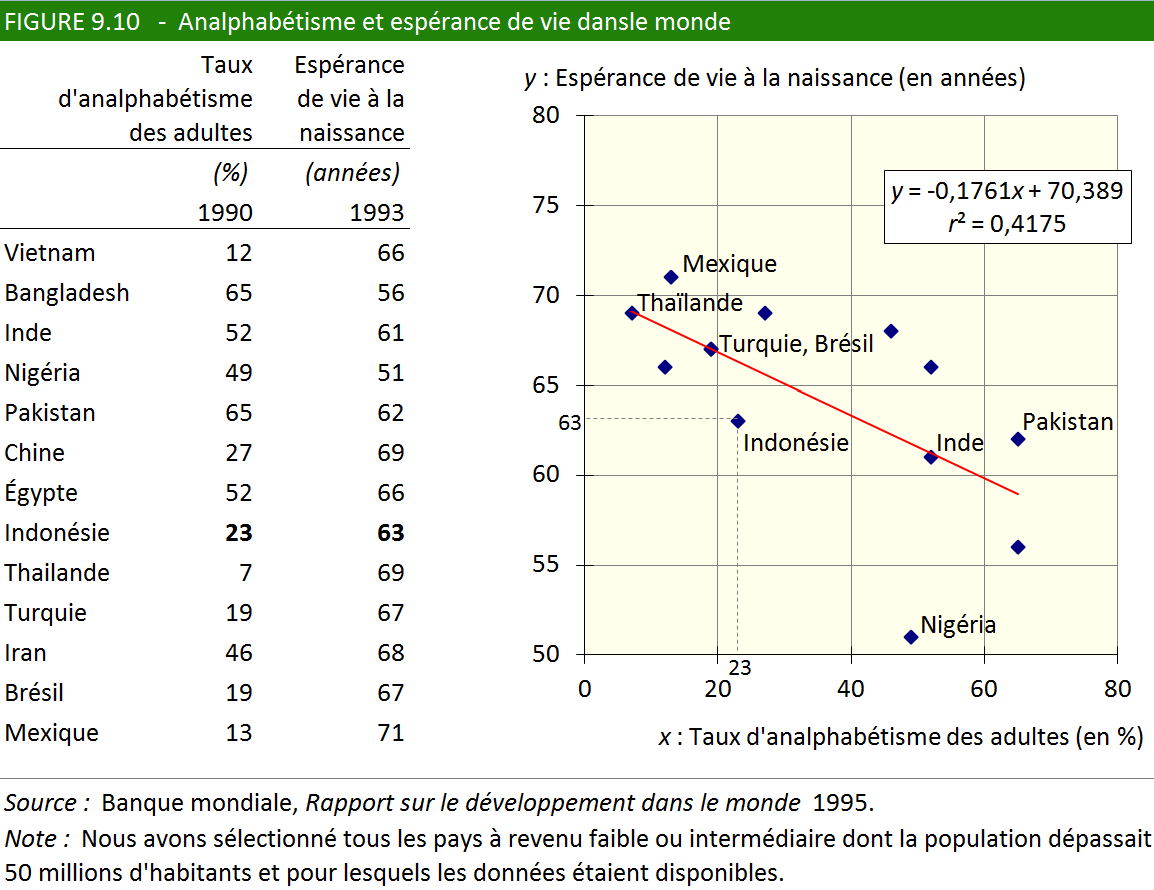
forme d’un tableau accompagné d’un graphique (voir figure 9.10).
Chacun des points du graphique représente un pays. Le point correspondant
à l’Indonésie, par exemple, a une abscisse de 23 (par rapport à l’axe
horizontal) et une ordonnée de 63 (par rapport à l’axe vertical).
On ne voit que 12 points sur le graphique, parce que deux pays, le
Brésil et la Turquie, possèdent exactement les mêmes valeurs. Étant
donné que le graphique a été tracé à l’aide d’un chiffrier électronique,
il n’a pas été difficile, en sélectionnant la bonne option, d’y rajouter
la droite de régression qui correspond à l’ensemble des points. Le
chiffrier a même eu la bonté de nous fournir l’équation de la droite
de régression (sous la forme y = bx + a), ainsi qu’un coefficient que nous interprèterons un
peu plus loin. Certes, les points du graphique sont loin d’être parfaitement
alignés, mais la droite donne quand même une tendance générale. On
peut affirmer, d’emblée, qu’il existe une certaine corrélation entre
l’analphabétisme et l’espérance de vie, et que ces deux variables
évoluent en sens inverse.
3.3. Le coefficient de corrélation
Comme nous l’avons indiqué un peu plus haut, le coefficient de corrélation
mesure la force de la relation entre les deux variables. Mais avant
d’interpréter ce coefficient, il faut le calculer. Pour ce faire,
il existe deux méthodes : la méthode facile (en utilisant les fonctions
intégrées d’un chiffrier électronique) et la méthode à papa (en se
tapant une série de calculs, simples mais laborieux). Nous avons déjà
fait connaissance avec la méthode facile, puisque nous l’avons utilisée
pour tracer la droite de régression et obtenir gratuitement l’équation
de la droite et un certain coefficient (r²) qui n’est autre
que le carré du coefficient de corrélation (revoir le graphe de la figure 9.10).
La méthode à papa.
Dans le tableau 9.5, nous indiquons toutes les étapes du
calcul du coefficient de corrélation et des paramètres de la droite
de régression et nous reproduisons les formules correspondantes. Si
vous disposez d’un chiffrier électronique (c’est presque indispensable
dès qu’on utilise des chiffres en sciences humaines), vous pouvez
vous dispenser de cette étape fastidieuse.
Plus le coefficient de corrélation est proche de 0, moins
la corrélation est forte.
Le coefficient de corrélation est construit de telle sorte qu’il est
égal à +1 ou –1 lorsque les points sont parfaitement alignés. Dans
notre exemple, le coefficient de corrélation est égal à –0,646. Le
signe négatif indique que les deux variables évoluent en sens inverse.
La valeur absolue du coefficient (0,646) semble relativement élevée,
mais pour l’interpréter il est nécessaire de tenir compte de la taille
de l’échantillon. On pourra alors, moyennant certains calculs supplémentaires,
faire une hypothèse sur l’existence d’une association entre les deux
variables et la tester avec la table de distribution de Student. Si
vous tenez vraiment à savoir comment, il vous faudra consulter un
ouvrage spécialisé.
EXERCICES 3
1. Échalote, Bouboule, Brummel et les autres
Vous devez évaluer s’il existe une corrélation entre le poids
et la taille à l’aide d’un échantillon d’au moins 30 individus.
(Pour les besoins de la cause, il est acceptable que l’échantillon
ne soit pas tiré au hasard.) Tracez le nuage de points et calculez
le coefficient de corrélation (à la main ou en utilisant le chiffrier
électronique, calcul fourni)
2. Étranges corrélations
Les corrélations présentées ci-après paraissent pour le moins étranges. À vous de leur donner une explication logique et identifiant convenablement les variables impliquées et les relations qui les unissent.
a) On a observé une corrélation entre homicides et pointures des souliers. Plus précisément, il semble que les homicides soient plus fréquemment commis par des individus possédant des pieds plus grands que la moyenne.
b) On a déjà constaté, en Californie, une corrélation entre les ventes de bière et le taux de mortalité chez les personnes âgées et les bambins.
4. LES ACCIDENTS DE LA ROUTE
Les jeunes sont-ils susceptibles de provoquer plus d’accidents que
leurs aînés? Les femmes conduisent-elles mieux que les hommes? Est-il
plus dangereux de rouler en Chine qu’aux États-Unis? Nous essaierons
de répondre, partiellement, à toutes ces questions en nous servant
de tous les outils vus dans ce chapitre.
4.1. Un bref tour du monde
Examiner quelques données brutes pour découvrir le schéma
de variables.
Commençons par déblayer le terrain en examinant quelques données brutes
publiées par le gouvernement japonais dans les années 1990. Nous reproduisons dans le tableau
9.6 le nombre d’accidents de la route et le nombre de victimes
de ces accidents pour six pays. Si les États-Unis se classent premiers,
devant le Japon, au chapitre des accidents et du nombre de blessés,
c’est la Chine qui détient le triste record du nombre de tués.
Le tableau 9.6 contient également quelques données concernant le Québec et couvrant quatre décennies. On y constate que le nombre d’accidents et de victimes tend à diminuer considérablement avec le temps, malgré l’augmentation du nombre d’automobiles sur les routes.
Ce premier contact chiffré avec la situation étudiée nous permet de
prendre conscience de la complexité du problème. Il est clair que
l’habileté des conducteurs ou l’état des routes ne sont pas les seules
variables qui peuvent exercer une influence sur le nombre d’accidents. Aux États-Unis,
il y a plus de kilomètres de routes qu’au Japon (pays plus petit)
et plus de véhicules qu’au Canada (pays moins peuplé) et qu’au Mexique
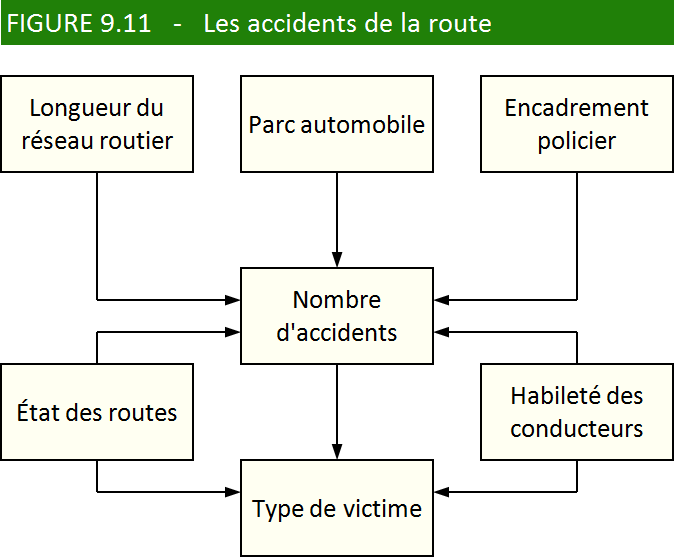
(pays moins riche). La figure 9.11 illustre une façon de relier ces
différentes variables ainsi que d’autres.
Il est plus difficile de comparer des situations hétérogènes.
Dans le tableau 9.6, avez-vous remarqué la situation anormale de
la Chine qui compte 25 fois moins de blessés mais plus de tués que
les États-Unis (dans ce dernier cas, s’agit-il de piétons?). Cela pourrait bien être attribuable
en bonne partie à la façon dont chaque pays définit chaque variable :
si tout le monde s’entend sur ce qu’est un tué, il en va autrement
pour les notions d’accident et de blessé. Nous éviterons ce genre
d’écueil en restreignant maintenant notre étude au Québec.
4.2. La situation dans les régions du Québec
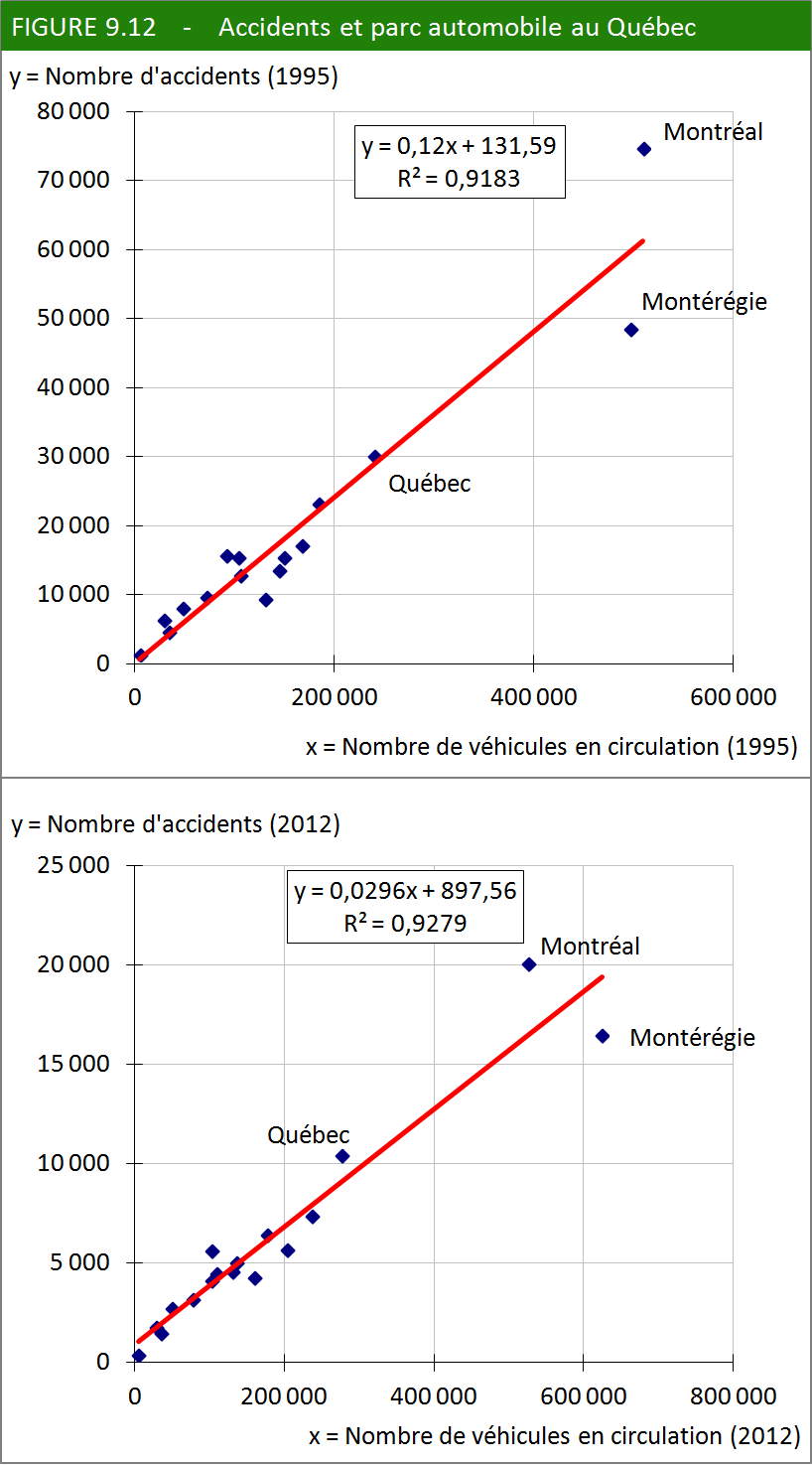
Dans la figure 9.12, nous avons choisi de relier la variable nombre
de véhicules à la variable nombre d’accidents en examinant
la situation dans les diverses régions du Québec. La figure est accompagnée
d’une droite de régression, entièrement construite avec un chiffrier
électronique et sans aucun calcul. La relation entre les deux variables
saute aux yeux. Le coefficient de corrélation (r) est très proche
de 1, ce qui signifie que la corrélation est très forte. Il reste
néanmoins que le nombre de véhicules n’explique pas entièrement le
nombre d’accidents. Il vaudrait la peine de chercher à isoler les
autres variables.
Il existe une explication relativement évidente à la situation de Montréal et de la Montérégie, dont les points s’écartent étrangement — et symétriquement — de la droite de régression. De nombreux conducteurs de la Montérégie se rendent chaque jour à Montréal. En même temps que les automobilistes, les risques d’accident se déplacent alors d’une région à l’autre. Le même phénomène entre les villes-centres et leur grande banlieue se remarque, à moins grande échelle, dans la région de Québec en 2012.
Dans les Cahiers de géographie du Québec d’avril 1996, des chercheurs ont utilisé des variables plus raffinées pour
étudier la situation : la densité d’accidents (nombre d’accidents au km²), le taux de motorisation (nombre de véhicules de
promenade par habitant), la densité de la population (nombre d’habitants
par km²) et l’encadrement policier (nombre de policiers
pour 1000 habitants). On remarque que ces quatre variables sont en
réalité des rapports, ce qui permet de comparer des régions dont les
caractéristiques sont différentes. Les chercheurs ont alors calculé
la valeur de ces variables pour chacune des municipalités régionales
de comté du Québec et ont ensuite cherché à établir des corrélations.
Cette étude montre qu’au Québec, la densité d’accidents est directement
reliée à la densité de la population. L’équation de régression qui
relie ces deux variables est la suivante :
Selon cette équation, une région qui compterait 10 habitants/km²
aurait une densité annuelle d’accidents de 0,0084 + (10 x 0,0053)
= 0,0084 + 0,053 = 0,0614 accident/km². Le coefficient de
corrélation est de 0,99, ce qui indique que les deux variables se suivent de très près.
Lorsque l’on croise les variables densité d’accident et encadrement
policier, la corrélation est beaucoup plus faible (r = –0,37) et
les variables évoluent en sens inverse. Même si la présence policière
semble calmer les chauffards, son influence semble relativement faible
par rapport à d’autres variables. Notons enfin que des calculs similaires
effectués dans les 52 districts de gendarmerie de la Belgique donnent
des résultats très semblables. Ce genre d’étude peut être particulièrement
utile lorsqu’il s’agit de mettre en place une politique de sécurité
routière.
4.3. Qui conduit le mieux?
Nous nous demandions un peu plus haut si le sexe ou l’âge peuvent
exercer une influence sur le nombre d’accidents. Le tableau 9.7
montre qu’il y a relativement moins de femmes que d’hommes
qui se trouvent impliqués dans des accidents au Québec. Mais ici encore,
il faut être prudent avant de conclure que les femmes conduisent mieux
(ou se soûlent moins) que les hommes. On devrait se poser les questions
suivantes : lequel des deux sexes fait le plus de kilomètres dans l’année?
Lequel roule le plus la nuit? Lequel fréquente le plus souvent des
routes de campagne? Etc.?
Dans le tableau 9.7, on constate à nouveau que le nombre d’accidents a tendance à baisser fortement au Québec sur le long terme, encore plus pour les hommes que pour les femmes. Cela dit, la très grande majorité des conducteurs n’ont pas eu d’accident au cours de l’année considérée.
Dans le tableau 9.8, on constate que les jeunes conducteurs
ont relativement plus d’accidents que leurs aînés. Mais là
encore, le phénomène peut être influencé par plusieurs variables :
l’expérience du conducteur, son attitude, l’état des routes qu’il
fréquente particulièrement et l’âge du véhicule.
Pour les deux tableaux précédents, nous avons calculé le Khi carré
et le V de Cramer. Étant donné que l’échantillon est très grand (il
s’agit en réalité de la population au complet), le Khi carré est très
élevé. Nos données sont, par définition, représentatives, aussi il
est inutile de faire un test d’hypothèse. Le Khi carré nous sert uniquement
à calculer la force de l’association grâce au V de Cramer. On constate,
dans le tableau 9.8 que le V de Cramer est de 0,083 en 1995. Cela
signifie que si l’âge explique une partie du problème, il est très loin
de l’expliquer dans son entier. Bien que faible, le coefficient de
Cramer s’avère intéressant si on cherche à comparer la situation de
1995 à celle de 1991 ou de 2012, par exemple. Le V de Cramer était alors de 0,077,
ce qui prouve qu’il existe une certaine stabilité dans la relation.
4.4. Des calculs plus simples en disent parfois plus long
Pour tirer les choses au clair, mettons de côté les coefficients compliqués
et servons-nous de simples rapports. Selon une enquête concernant
la région de l’Outaouais (1995), les hommes au volant sont impliqués 3,5
fois plus souvent que les femmes dans des accidents mortels. Ce rapport
baisse à 1,8 pour les accidents avec blessures légères. Par ailleurs,
les conducteurs parcourent deux fois plus de distance que les conductrices.
Cela démontre qu’à distance égale parcourue, les conducteurs masculins
ont plus d’accidents que les femmes, du moins en ce qui concerne les
accidents graves.
Pour mieux cerner la relation entre l’âge et la fréquence
des accidents, nous avons calculé le nombre d’accidents par rapport
au nombre de titulaires de permis de conduire pour différents groupes
d’âge. Les chiffres, que nous reproduisons dans le tableau 9.9, parlent
d’eux-mêmes (troisième colonne du tableau).
EXERCICES 4
1. Mon camion c’est ma maison
Commentez le tableau 9.10.
2. Jeune et fou
a) Complétez le tableau 9.11.
b) Tracez sur un graphe la courbe du rapport Accidents/Détenteurs de permis en fonction de l’âge. Tracez une deuxième courbe sur le même graphe
en utilisant les données de 1995 (voir tableau 9.9).
c) Comparez la situation de 1991 à celle de 1995 et commentez.
3. Recherche
Mettez à jour les tableaux 9.7, 9.8 et 9.9, et commentez l’évolution des données.
EXERCICES SUPPLÉMENTAIRES
1. Des relations à vérifier
La pauvreté est en hausse aux États-Unis dans les années 1990. Une
idée très répandue dans les milieux conservateurs veut que l’augmentation
des dépenses de l’aide sociale soit causée par la prolifération des
mères adolescentes et des mères célibataires. Dans d’autres milieux,
soi-disant progressistes, on affirme souvent que l’instruction n’est
plus un moyen efficace pour éviter la pauvreté. Avant de commenter
ces affirmations, répondez aux questions a et b ci-après.
a) Représentez graphiquement les données suivantes : le salaire mensuel
moyen est de 508 $ pour ceux qui n’ont pas terminé leurs études secondaires,
de 1080 $ pour ceux qui détiennent un diplôme du secondaire, de 1303 $ pour
ceux qui ont entamé des études postsecondaires et de 2339 $ pour ceux
qui ont terminé des études universitaires.
b) Représentez graphiquement les données suivantes : l’âge médian des
mères qui bénéficient de l’aide sociale est de 27,4 ans, 24,5 % d’entre
elles ont moins de 21 ans et 7,1 % d’entre elles ont moins de 18 ans.
(Source des données : Scientific American, octobre 1996, données de
1993 et 1995.)
2. Le suicide selon Durkheim
Dans un ouvrage classique intitulé Le suicide, Émile Durkheim
constate que, si chaque suicide est un phénomène individuel, le taux
de suicide d’une population s’avère facilement prévisible à court terme.
Entre 1871 et 1875, le taux de suicide (nombre annuel de suicides pour 100 000 habitants) était de 25,5 au Danemark et de 3,5 en Italie. En Suisse, en 1876, il variait de 8,3 à 8,7 chez les catholiques et de 29,3 à 45,6 chez les protestants.
En France, entre 1835 et 1843, ce taux était de 30,6
en été, de 28,3 au printemps, de 21,0 en automne et de 20,1 en hiver. Entre 1848 et 1857,
il s’élevait à 4,6 pour les gens de 16 à 21 ans, à 9,8 pour ceux
de 21 à 30 ans, à 11,5 pour ceux de 31 à 40 ans et à 16,4 pour ceux de
41 à 50 ans. Entre 1889 et 1891, ce taux de suicide chez les hommes mariés âgés de 26 à 35
ans était de 10,6 contre 25,7 chez les hommes célibataires. Chez les
femmes mariées du même groupe d’âge, ces taux étaient respectivement de 2,8 et de 6,1 chez les célibataires. Durkheim note d’autre part que le taux est
plus élevé dans les grandes villes que dans les petites, plus élevé
le jour que la nuit, plus élevé au début de la semaine qu’à la fin.
Par ailleurs, des données relevées au XXe siècle indiquent que le taux de suicide
était au plus bas en 1917 (14,0) et en 1943 (11,3) alors qu’il atteignait
un sommet en 1912 (22,9) et en 1934 (21,7).
Au Québec, le taux de suicide passait de 4,2 en 1950-54 à 13,8 en 1975-79. En
1995, le taux de suicide était de 58 en Hongrie, de 30,0 en France, de 34,0
en Suisse, de 12,0 en Espagne et de 20,4 aux États-Unis. Du côté des personnes de 75 ans et plus, le taux de suicide se révèle 12 fois plus élevé pour les hommes
que pour les femmes pour atteindre 186,2 en Hongrie et 114,0 en France.
Voici pour terminer quelques comparaisons entre pays pour la période 2001-2010. Le taux de suicide du Canada était de 17,3 contre 17,7 aux États-Unis. Celui du Japon était de 36,2 contre 13,0 en Inde. Celui de Cuba était de 19,0 contre 3,9 en République dominicaine, celui de la Russie était de 53,9 contre 37,8 en Ukraine.
(Sources : Émile Durkheim, Le suicide, 1897, réédition 1960 : Presses
universitaires de France. Organisation mondiale de la Santé. Marie-France
Charron, Le suicide au Québec, 1983. PNUD, Rapport sur le développement humain 2014.)
a) Construisez un schéma contenant toutes les variables qui influent
sur le taux de suicide. Indiquez par des flèches le sens des relations.
Lorsque cela est pertinent, accompagnez la flèche d’un signe positif
ou négatif pour indiquer si les variables évoluent dans le même sens
ou en sens inverse.
b) Recherche. Obtenez d’autres données dans le but de confirmer, de
rectifier ou de compléter le schéma de variables que vous venez de
tracer.
3. Ex-maltraité, future brute?
Joan Kaufman et Edward Zigler, de l’université de Yale, ont essayé
d’établir si la violence parentale envers les enfants se transmettait
de génération en génération. Pour ce faire, ils ont utilisé les résultats
d’une enquête menée auprès de 282 parents d’enfants admis dans un
service de soins intensifs pour enfants. Ils constatèrent que 49 de
ces parents avaient été maltraités durant leur enfance et que 10 de
leurs enfants furent maltraités dans l’année qui suivit leur visite
à l’hôpital. Parmi ces 10 enfants, 9 étaient issus de parents qui
avaient été maltraités eux-mêmes. (Source : Sciences humaines, no 65,
octobre 1996.)
a) Construisez, à partir des données ci-dessus, un tableau croisé
de deux colonnes et de deux lignes.
b) Faites un test pour vérifier l’hypothèse qu’il existe une relation
entre la façon dont les parents ont été traités dans leur enfance
et la façon dont ils traitent leurs enfants.
c) Commentez l’affirmation suivante : « 90 % des enfants maltraités
sont issus de parents eux-mêmes maltraités dans leur enfance, mais
seulement 18 % des ex-enfants maltraités deviennent des parents maltraitants ».
4. Deux variables qui se suivent de près
a) Représentez les points du tableau 9.12 sur un graphe.
b) Commentez le graphe.
c) Si vous avez un chiffrier électronique, essayez de tracer une droite
de régression sur le même modèle que la figure 9.12.
5. Un sport dangereux?
Quelque 223 hockeyeurs qui ont été admis à l’urgence de l’hôpital
de l’Enfant Jésus de Québec, entre le 1er octobre 1991 et le 30 avril
1992. Le tableau 9.13 indique comment se répartissaient
les blessures selon le type de jeu pratiqué et la partie du corps
touchée.
Essayez d’établir s’il existe une relation entre le type de hockey
pratiqué et le type de blessure reçue. Si nécessaire, réduisez le
tableau à deux lignes, en regroupant certaines catégories.
6. Recherche : un tableau croisé
Faites une mini enquête qui vous permettra de construire un tableau
croisé. Choisissez deux variables qualitatives comportant chacune
de deux à quatre catégories. Constituez un échantillon (aléatoire
dans la mesure du possible) et compilez vos résultats dans un tableau
croisé. Si nécessaire, augmentez la taille de votre échantillon pour
éviter que certaines cases du tableau ne contiennent des fréquences
inférieures à 5. Calculez le Khi carré et le V de Cramer et commentez les
résultats.
7. Recherche : l’héritabilité du poids
Dans cette mini enquête, vous chercherez à mesurer la corrélation
entre le poids (ou la taille) des pères et de leurs fils, ou des mères
et de leurs filles.
Prenez une balance (ou un mètre) et promenez-vous dans votre quartier.
Pesez les paires (parent-enfant) tout en ménageant leur susceptibilité.
Notez leur âge et vérifiez si vous êtes en présence d’un parent biologique
ou d’un parent adoptif. Pour éliminer l’influence de la variable âge,
prenez uniquement des enfants adultes ou, à la rigueur, des enfants
d’un âge précis.
Tracez un nuage de points. Tracez la courbe de tendance. Calculez
le coefficient de corrélation.
Que proposez-vous pour améliorer l’échantillon choisi?







 1.1. Sagesse populaire
1.1. Sagesse populaire