La personne qui s’intéresse aux sciences humaines demeure parfois
perplexe devant un tableau présentant des chiffres. Il est pourtant
facile de lire et interpréter un tableau si on respecte quelques règles
de base. Ce sont ces principes que nous allons étudier dans ce chapitre.
Nous profiterons aussi de l’occasion pour faire la synthèse de plusieurs
notions vues jusqu’ici, avant de nous lancer dans la deuxième partie
de ce manuel.
Nous commencerons par présenter, dans une première section, les principes
simples qui permettent de faire de l’analyse de tableau une activité
riche d’enseignements. Puis nous proposerons, dans les trois autres
sections, trois situations typiques, toutes reliées à différents
domaines des sciences humaines. La première situation sera présentée
sous forme de tableaux, la deuxième sous forme de graphiques (une
manière d’« habiller » un tableau) et la dernière sous forme de texte
(une façon de « noyer » un tableau). Nous verrons que ce sont à peu
près toujours les mêmes principes qui s’appliquent dans tous les cas.
Vous disposerez alors d’une arme redoutable pour comprendre (en lisant
des tableaux) et faire comprendre (en produisant vos propres tableaux)
les aspects quantitatifs de la réalité humaine.
Au terme de ce chapitre, vous devriez être en mesure de répondre aux questions suivantes :
Comment peut-on tirer le maximum de l’analyse d’un tableau?
Pourquoi est-il primordial de bien cerner la population et les caractéristiques de la population sur laquelle portent les observations consignées dans un tableau?
Comment peut-on transformer les données d’un tableau pour les rendre plus explicites?
Comment un tableau peut-il être générateur d’hypothèses?
Comment peut-on construire ses propres tableaux?
1. TROIS CLÉS : DÉFINIR, OBSERVER, INTERPRÉTER
L’analyse d’un tableau se fait en trois temps. On commence par définir
les éléments qui constituent le tableau. Puis on se met à observer
les données elles-mêmes. Enfin, on cherche à interpréter
les données observées. Pour parler plus simplement, on se pose successivement
les trois questions suivantes : de quoi parle-t-on? Quels sont les chiffres? Que signifient-ils?
Ces trois étapes sont décrites de façon détaillée dans les paragraphes
qui suivent. Toutefois, il est bien connu qu’on est souvent plus pressé
d’écouter de la musique que de lire le mode d’emploi de l’appareil audio qu’on vient d’acheter. Si c’est votre cas, vous pouvez passer directement
aux applications qui nous servent à illustrer la démarche, quitte
à vous y référer au fil des commentaires.
1.1. La démarche à suivre
A. Définir les éléments du tableau
À cette étape-ci, on considère surtout la structure du tableau et non pas ce qui s’y trouve.
1. À quelle population le tableau fait-il référence et
sous quel angle (quelles caractéristiques) la population est-elle
étudiée? Quelle est l’échelle de mesure de ces caractéristiques? Dans
quelle unité les données sont-elles exprimées? Les données sont-elles
brutes ou dérivées? En d’autres termes, résultent-elles d’un traitement quelconque? Si
elles sont dérivées, s’agit-il de proportions, d’autres rapports,
de moyennes, de taux de variation, d’indices?
2. Y a-t-il des relations entre les variables? Si
oui, qui dépend de quoi? Pour répondre à ces deux questions,
il faut déterminer les variables, compte tenu
de ce que l’on cherche à comprendre. On peut, par exemple, considérer chaque
caractéristique de la population comme une variable. Dans d’autres
cas, on peut trouver plus intéressant de considérer chaque « colonne »
de chiffres comme une variable.
3. Quel est le domaine étudié (le sujet, le lieu,
l’époque)? Les données sont-elles chronologiques (évolution sur une
période donnée, et avec quelle fréquence) ou statiques (photographie
à un moment précis)? Les données sont-elles homogènes (y compare-t-on
les mêmes années, les mêmes réalités)? Quelles sont les sources des
données? Ces sources sont-elles fiables? Peut-on les consulter?
B. Observez les données
Ce n’est qu’à partir d’ici qu’on commence réellement à regarder les
chiffres proprement dits.
1. Décrivez l’évolution d’une des variables. Quelle
est son allure générale (valeurs habituelles, tendance à long terme,
changement radical) et quelles sont ses spécificités (évolution
à court terme, éléments particuliers)? Y a-t-il des valeurs ou des
variables inattendues?
2. Comparez les différentes variables (même si on
ne croit pas qu’elles sont nécessairement reliées). Se suivent-elles?
Vont-elles en sens inverse? Où s’arrêtent leurs relations?
3. S’il y a lieu, transformez les données (calculez
des rapports, des moyennes, des taux de variation, des indices) pour
faciliter l’observation ou mettre certains éléments en évidence. À
l’inverse, on peut essayer de reconstituer les données originales
(qui se cachent derrière des rapports ou des taux de variation, par
exemple).
C. Interprétez les données
Après avoir défini et observé les données, on essaie de comprendre
ce que les chiffres nous disent et ce qu’ils pourraient nous laisser
supposer.
1. Émettez des hypothèses qui pourraient expliquer
les faits observés.
2. Distinguez dans les hypothèses ce qui est démontrable
(d’après les données du tableau) de ce qui est spéculatif (c’est-à-dire
ce qui est seulement possible ou probable).
3. Recherchez d’autres données qui pourraient éclairer
(confirmer ou infirmer) les hypothèses.
1.2. Première application : Les fermes canadiennes
Ces étapes vous semblent sans doute un peu abstraites présentées ainsi.
Voyons, avec deux exemples concrets, comment on peut les appliquer
à des données réelles tirées d’un rapport sur l’activité humaine et
l’environnement.
Notre premier tableau a trait aux fermes canadiennes (tableau 6.1a).
A. Définir
La population à laquelle le tableau fait référence est l’ensemble
des fermes canadiennes. La caractéristique étudiée est la superficie
de chaque ferme (on aurait pu étudier d’autres caractéristiques comme
le revenu ou la grosseur du troupeau de vaches de chaque ferme). Théoriquement,
le tableau aurait pu être construit à partir d’une liste contenant
pour chaque ferme sa superficie respective. Le nombre de fermes constitue
l’effectif de la population et la superficie de chaque ferme est la
seule variable étudiée. La superficie est mesurée sur une échelle
de rapport et son unité de mesure est le million d’hectares (1 hectare
= 100 mètres × 100 mètres = 10 000 m²).
Il y a cependant une autre manière de voir les choses. Comme nous
ne possédons pas cette fameuse liste des fermes (qui n’a peut-être
d’ailleurs jamais existé comme telle) et puisqu’on nous donne des
chiffres sur l’évolution de trois éléments qui semblent reliés entre
eux, nous pouvons décider de considérer chaque colonne comme une variable :
1. superficie totale (en millions d’hectares), 2. nombre de fermes
(en milliers d’unités), 3. superficie moyenne (en hectares). On remarque
que les variables 1 et 3 utilisent la même unité de mesure de base,
mais avec un facteur différent, ce qui permet de mieux visualiser
les données*.
On note que notre variable 3 est une donnée dérivée (alors que les
autres variables sont des données brutes). Plus précisément, la variable
3 représente le rapport* entre la variable 1 et la variable
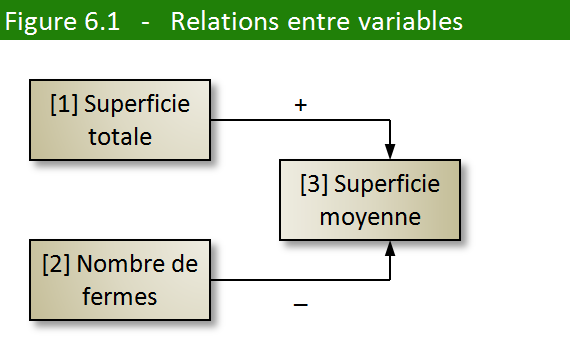
2. Le schéma de la figure 6.1 illustre la relation
entre les trois variables. La variable 1 influence la variable 3 de
façon directe : plus la variable 1 est grande, plus la variable
3 est grande. La variable 2 influence la variable 3 de façon inverse :
plus la variable 2 est grande, plus la variable 3 est petite. Sur
le schéma, nous indiquons le sens de la relation par le signe plus
(+) pour la relation directe et par le signe moins (–) pour la relation
inverse.
Pour terminer cette première étape (définir), voici quelques mots sur le domaine couvert.
Le sujet étudié est l’agriculture. Les données sont chronologiques.
Elles portent sur une période d’environ un siècle et l’intervalle entre
chaque relevé (la périodicité) est de 10 ans. Il s’agit d’une période
et d’intervalles relativement longs (par rapport à une vie humaine
par exemple) : on nous présente une évolution à long terme. Les données
portent sur l’ensemble du Canada. Le document est publié par Statistique
Canada et peut être consulté facilement, si nécessaire.
B. Observer
La superficie totale cultivée au Canada (variable 1) augmente rapidement
au début du XXe siècle. Par la suite, elle plafonne puis elle décline
légèrement à partir de 1951. Le nombre de fermes (variable 2) augmente
aussi au début du XXe siècle, quoique de façon apparemment moins rapide
que pour la variable 1, plafonne dès les années 1930 et décroît ensuite
de façon systématique, surtout après la Deuxième Guerre mondiale.
La superficie moyenne des fermes (variable 3) ne cesse d’augmenter
tout au long de la période considérée.
Pour mieux observer la vitesse à laquelle se produisent les changements,
on pourrait calculer des taux de variation pour chaque décennie (tableau
6.1b). On a alors la confirmation que la superficie totale (variable
1) a augmenté plus vite que le nombre de fermes (variable 2) jusqu’en
1931. Le calcul des taux de variation permet de mettre clairement
en évidence une valeur particulière : de 1931 à 1941, la superficie
moyenne a très peu augmenté (colonne 3).
C. Interpréter
Que peut-on conclure de ces observations? Il va de soi que cette partie
est la plus délicate, car émettre des hypothèses, c’est jouer sur
un terrain glissant. C’est pourtant ce que nous avons fait tout au
long de ce manuel, non pas en prétendant découvrir une vérité absolue,
mais dans le but de stimuler la réflexion. Après tout, pour un chercheur
débutant, il faut commencer par avoir de nombreuses idées avant de détenir
quelques rares certitudes.
Commençons par ce qui est démontrable par la simple logique. Il est
clair que l’évolution de la variable 3 s’explique par la variation
des 2 autres (revoir la figure 6.1). La superficie moyenne augmente
d’abord à cause d’une augmentation plus rapide de la superficie totale
que du nombre de fermes (jusqu’en 1941). Par la suite, la variable
3 augmente à cause de la baisse de la variable 2.
On peut imaginer que, jusque dans les années 1930, une partie du territoire
cultivable canadien était encore vierge. Cette hypothèse doit pouvoir se vérifier
facilement, et si jamais on s’apercevait du contraire, les choses s’avèreraient encore plus intéressantes. Le léger déclin après 1951 peut
s’expliquer par l’empiètement des villes sur les terres agricoles
et l’abandon de terres peu fertiles. Tout au long du siècle, les progrès
techniques (machines agricoles, recherche biologique, mise en marché,
informatisation) ont à la fois permis et exigé l’exploitation de surfaces
de plus en plus grandes avec de moins en moins de travailleurs. Certains
fermiers ont dû vendre et quitter le métier, d’autres se sont agrandis.
Comme la plupart des fermes sont des entreprises familiales (hypothèse
à vérifier aussi), la superficie moyenne augmente, mais pas trop rapidement :
il faut que le cultivateur demeure capable de gérer son espace.
On serait tenté de croire, à première vue, que le ralentissement observé
dans les années 1930 (la superficie moyenne augmentant très peu comparativement
aux autres périodes) est causé par la dépression économique qui sévissait
alors. On pourrait faire l’hypothèse que les gens s’accrochaient à
la ferme comme à un refuge dans une époque de chômage endémique, d’où une hausse
du nombre de fermes. On pourrait aussi émettre l’hypothèse que beaucoup
de fermiers endettés devaient céder leur propriété aux créanciers
(d’où une baisse du nombre de fermes). Ces deux hypothèses, dont les
effets sont contradictoires, mériteraient une recherche plus approfondie.
Cependant, n’y a-t-il pas une explication plus simple? Au cours des années 1930,
la superficie cultivée a déjà cessé d’augmenter (colonne 1 du tableau
6.1b) alors que le nombre de fermes ne commencera à baisser que
dans la décennie suivante (colonne 2). On est assis entre deux chaises :
il n’est alors pas étonnant que la hausse de la superficie moyenne marque
un léger temps d’arrêt pendant cette période charnière (colonne 3).
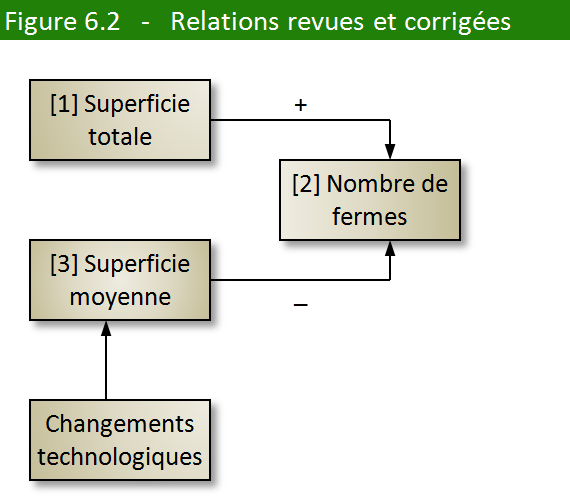
Nous avons affirmé précédemment que la superficie moyenne (variable
3) dépend des deux autres variables (superficie totale et nombre de
fermes). Cela paraît évident sur le plan mathématique parce que la
superficie moyenne s’obtient en divisant la superficie totale
par le nombre de fermes. Toutefois, sur le plan humain, n’est-ce
pas le contraire qui se produit? N’est-ce pas l’augmentation systématique
de la superficie moyenne des fermes, en raison des progrès de la mécanisation,
de la gestion, de la recherche génétique, etc., qui est la cause de
l’accroissement des exploitations agricoles et, par conséquent, de
la disparition ou de la fusion d’un grand nombre de fermes (voir la
figure 6.2)?
Au terme de cette première tentative, certains lecteurs pourraient
se dire qu’analyser un tableau est une chose bien compliquée : nous
semblons hésiter sur le choix des variables et la façon dont elles
s’influencent. C’est vrai, il n’y a pas de recette magique, mais n’avez-vous
pas l’impression que cette démarche vous a permis de comprendre bien
des choses? Derrière la froideur des chiffres, on peut découvrir un
univers humain riche et passionnant.
1.3. Seconde application : La morue se fait rare
Quel rapport entre la morue et les sciences humaines, diront certains?
Cela nous paraît pourtant évident. La pêche, tout comme l’agriculture,
illustre les relations entre l’être humain et la nature. Nous nous intéresserons particulièrement au tournant des années 1990, lorsque les stocks de morue, réputés inépuisables depuis une époque antérieure à la découverte du Canada, s’effondrèrent brusquement.
A. Définir
Dans le tableau 6.2, on pourrait considérer qu’il n’y a qu’une variable
(les prises de morues) et que cette variable (mesurée en milliers
de tonnes) est distribuée sur une échelle nominale qui contient deux
catégories : pêcheurs canadiens et pêcheurs étrangers.
Ici encore, on pourrait voir les choses autrement dans l’espoir de
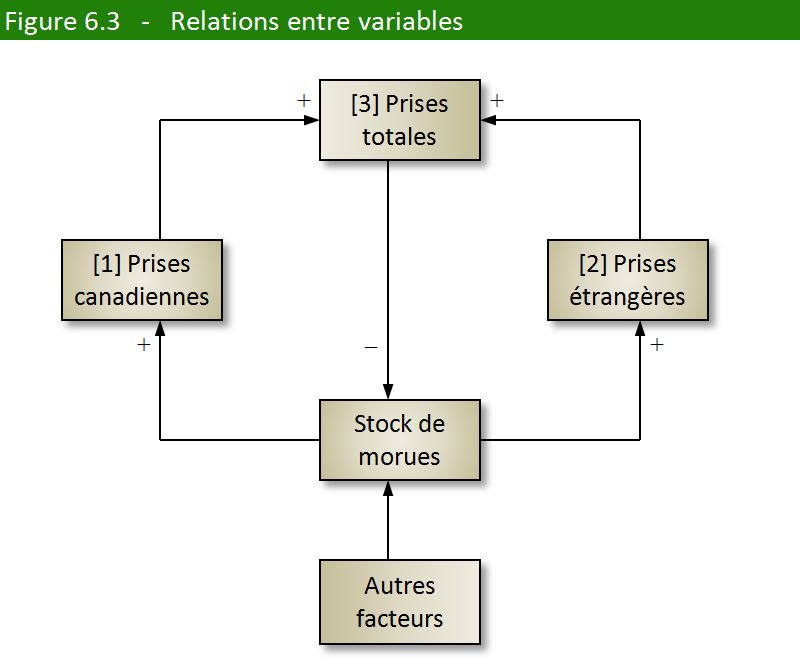
mettre en évidence les relations entre divers éléments. Nous aurions alors
trois variables : les prises canadiennes (variable 1), les prises étrangères
(variable 2) et les prises totales (variable 3). Ne perdons pas de vue que la variable 3 est la somme des deux
autres. Cette manière de voir peut se justifier si nous considérons que
ce qui sépare les pêcheurs canadiens et étrangers (traditions, lois,
conditions économiques, etc.) est plus important que ce qui les unit
(le stock commun de morues).
La figure 6.3 illustre cette façon de relier nos trois variables.
Il est clair que les prises (flux) diminuent les stocks
de morue et que la baisse des stocks de morue entraîne une baisse (volontaire
ou non) des prises. D’autres facteurs (température de l’eau, pollution,
courants) peuvent aussi influencer la façon dont les stocks se reproduisent.
Nous avons ici des données chronologiques. Compte tenu des circonstances
(saisons de pêche, cycle annuel de reproduction des poissons, utilisation des bateaux sur plusieurs années), la période (12
ans) et la périodicité (1 an) sont particulièrement bien choisies.
Elles nous permettent de mettre à la fois en relief les fluctuations
annuelles et l’évolution générale des prises à moyen terme.
On pourrait compléter le tableau 6.2 en calculant les proportions
respectives des prises canadiennes et étrangères dans le total et
en calculant des indices simples basés sur l’année 1980 = 100. Nous
vous laissons ce soin.
B. Observer
Les trois variables (les trois colonnes) fluctuent autour d’une même
valeur jusqu’en 1990. En d’autres termes, ça varie d’une année à l’autre
(phénomène à court terme), mais ça reste dans les mêmes ordres de grandeur
(phénomène à long terme). Puis on observe une chute (qui devient spectaculaire
en 1992).
C. Interpréter
Une façon de noyer le poisson serait d’une part pour le Canada d’accuser
les étrangers (les chalutiers espagnols) de ne pas avoir diminué leurs
prises assez rapidement (en 1991). Pour les étrangers, il s’agirait
de mettre en évidence le fait que le Canada (dont les prises sont
trois fois plus élevées que celles de l’étranger) n’avait besoin de personne
pour l’aider à exterminer les poissons. Ou peut-être que tout cela
est la faute de Brigitte Bardot, dont les campagnes anti-fourrure ont causé une prolifération du plus gros des consommateurs de morue, le vorace phoque!
EXERCICES 1
1. Les poissons chevauchants
a) Quelle est la population étudiée dans le tableau 6.3? Quelle est la variable? Quelle
est son échelle de mesure? Les données sont-elles brutes ou dérivées?
Quelle est leur unité de mesure? Dans le cas de la morue (tableau
6.2), la comparaison se faisait dans le temps. Qu’en est-il ici?
b) Calculez la répartition (en proportion du total) des prises de
chaque zone. Évaluez, à l’aide d’un rapport, l’importance des stocks
chevauchants dans la pêche mondiale.
c) Quel est l’intérêt d’étudier les poissons chevauchants?
2. Les amateurs de poisson
a) Quelle est la population étudiée dans le tableau 6.4? Quelle est la variable? Quelle
est son échelle de mesure? Les données sont-elles brutes ou dérivées?
Quelle est leur unité de mesure?
b) Comparez la consommation mondiale par habitant de poissons et coquillages
(dernière ligne du tableau 6.4) à la production mondiale par habitant
(que vous calculerez à partir des données du tableau 6.3). Commentez.
c) Observation. Quel genre de pays retrouve-t-on en tête (ou en queue,
ou au milieu)? Ont-ils des points communs?
c) Interprétation. Essayez de proposer des hypothèses historiques,
culturelles ou géographiques qui permettraient, une fois vérifiées,
d’expliquer les différences entre pays. Expliquez en particulier le
cas de l’Islande, du Portugal et de l’Autriche.
2. ANALYSER UN TABLEAU : FAUT-IL SE FAIRE DES CHEVEUX BLANCS?
La population vieillit en Occident, à ce qu’il paraît. Ce refrain ne date pas d’aujourd’hui, puisqu’on l’entendait déjà dans les années 1990. Comment voyait-on les choses à l’époque? Quelle fut la réalité 20 ans plus tard? Pour répondre à ces questions, retournons d’abord quelques décennies en arrière et plaçons-nous en pensée, au mois de février 1996, date à laquelle a été élaborée l’analyse de tableau qui va suivre.
Ce mois-là, le gouvernement canadien s’aperçoit soudainement que le régime
national de pension s’en va à vau-l’eau. Bref, les réserves seront
à sec en 2015. Le gouvernement canadien, face à cette triste découverte, laisse entendre qu’on devra
peut-être baisser le montant des pensions distribuées ou encore retarder
l’âge de la retraite. À Québec, tout en n’étant pas d’accord avec
Ottawa sur les solutions à apporter, on semble tout aussi surpris.
C’est comme si un météorite venait subitement de faire son apparition
dans l’orbite terrestre. Le peuple est inquiet et les élites promettent
seulement d’adoucir le choc inévitable.
Devant un aussi beau concert, il y a de quoi rester sceptique (on
a l’impression que les musiciens ont répété en cachette). Il est peu
probable que nos dirigeants aient attendu un jour de février 1996
pour se rendre compte qu’une personne née en 1950 aura pas mal de
chances d’atteindre les 65 ans en l’an 2015. Alors, il nous faut des
chiffres, s’il vous plaît! Compte tenu de ce que nous connaissons de la situation en 1996, nous voulons savoir, par exemple, si c’est
vrai qu’il y aura « trop » de personnes âgées en 2015. Par la
même occasion, nous tenterons de vérifier quelles seront alors les chances des futurs grands-pères et grands-mères, de dénicher
un éventuel partenaire du sexe opposé. Place au tableau 6.5; définissons, observons
et interprétons.
2.1. Définir
Le tableau 6.5 traite de la population du Québec à différentes périodes.
Cette population est vue sous deux angles : le groupe d’âge et le sexe,
que nous considérerons comme nos variables, et que nous étudierons
à travers le temps. À l’origine, l’âge se mesurait sur une échelle
de rapport, mais il a ici été découpé en classes et l’échelle est devenue ordinale. Ce découpage peut d’ailleurs
varier : selon ce qui nous intéresse, on regroupe ou on subdivise les
classes. Si, par exemple, on se préoccupe de la pression exercée par les
personnes à charge sur celles qui sont actives, on pourrait diviser
l’âge de la population en trois catégories : les « enfants », les « personnes
actives » et les « retraités ». Il va de soi que ces catégories ne sont
pas tranchées au couteau, par contre, il faut bien leur attribuer
des bornes précises. Pour le sexe, les choses sont plus simples (il
n’y en a que deux) : l’échelle est nominale.
Nos variables retenues : l’âge et le sexe.
Nous aurions pu traiter chaque colonne du tableau comme une variable
séparée, ainsi que nous l’avons suggéré dans les exemples précédents. Nous ne le
ferons pas, car nous nous intéressons en premier lieu à l’âge des gens,
et accessoirement à leur sexe. Si vous examinez le tableau 6.5, vous
verrez en effet que le sexe a manifestement une influence sur la longévité.
Nos deux variables, l’âge et le sexe, s’avèrent donc particulièrement bien choisies.
Examinons maintenant les dix colonnes du tableau 6.5. Pour mieux comprendre comment lire chacune de ces colonnes, imaginons ce qui se cache derrière chaque ligne de ce tableau 6.5, et pour cela regardons le tableau 6.6, qui ne contient aucun chiffre, mais seulement une structure.
Seules les trois premières colonnes du tableau nous fournissent des
données brutes. Chaque chiffre de la colonne 1 du tableau 6.5 correspond
par exemple à (H4 + H5) dans le tableau 6.6.
Dans les colonnes 4 à 6, nous avons des rapports entre les valeurs
prises par les catégories d’une même variable (Homme/Femme). Chaque
chiffre de la colonne 4 du tableau 6.5 correspond par exemple à (H3
/ F3) dans le tableau 6.6. Les données sont exprimées en pourcentage
(comme d’ailleurs pour les colonnes suivantes).
Dans les colonnes 8 à 10, nous avons encore des rapports entre catégories,
mais cette fois il s’agit l’autre variable (l’âge). Chaque chiffre
de la colonne 8 du tableau 6.5 correspond par exemple à (H4 + F4 +
H5 + F5)/(H1 + F1) dans le tableau 6.6.
Nous n’avons pas oublié la colonne 7 qui représente la proportion
de personnes de 65 ans et plus (la partie) dans la population (le
tout). Chaque chiffre de la colonne 7 du tableau 6.5 correspond
à (H4 + F4 + H5 + F5)/(Total global) dans le tableau 6.6.
2.2. Observer
Au lieu de parler de telle ou telle classe d’âge, nous emploierons
parfois des termes plus imagés (enfants, personnes âgées,
retraités, etc.). On se réfèrera au tableau 6.5 pour la définition
précise de chaque classe d’âge.
Colonnes 1 à 3 : une augmentation qui commence à ralentir
Le nombre de personnes âgées (de 65 ans et plus) augmente rapidement
entre 1961 et 1991 et cette croissance va en s’accélérant. La croissance
ralentit par contre entre 1991 et 1993 (et là, il faut considérer que
l’intervalle n’est que de 2 ans au lieu de 10 ans : voir les calculs
ci-dessous). Nous n’avons aucune indication sur l’augmentation du
reste de la population, même si nous pouvons nous douter qu’elle a
été moins rapide (ça fait déjà un point qui mériterait d’être vérifié).
Parmi les personnes âgées, c’est le nombre de femmes qui augmente
le plus vite. En effet, l’écart relatif se creuse entre hommes et
femmes âgés au cours des années ou, vu sous un autre angle et de façon
très approximative, le nombre de femmes âgées triple en 30 ans alors
que le nombre d’hommes âgés ne fait que doubler.
Quelques calculs pour vérifier tout cela.
Taux de variation entre 1961 et 1971 : (419,3 – 306,3)/
306,3 = 36,9 %
Taux de variation entre 1971 et 1981 : (573,9 – 419,3)/
419,3 = 36,9 %
Taux de variation entre 1981 et 1991 : (781,2 – 573,9)/
573,9 = 43,6 %
Entre 1991 et 1993, la population âgée est multipliée par 827,2/
781,2 = 1,059 (soit un taux de variation de 5,9 %, car 1,059 – 1 =
0,059 = 5,9 %). Si la même tendance devait se maintenir pendant 10
ans (c’est-à-dire si la population est multipliée par 1,059 tous
les deux ans cinq fois de suite), la population serait multipliée
par 1,0595 = 1,332 au bout de 10 ans. En d’autres termes, le
taux de variation entre 1991 et 2001 serait de 33,2 %, car 1,332 – 1 = 0,332 = 33,2 %. (Pour le rapport entre le taux de variation et l’indice de variation, revoir le chapitre 4.)
Taux de variation entre 1991 et 2001 (« si la tendance se
maintient ») : 33,2 %.
Nous disions aussi que l’écart se creuse entre hommes et femmes âgés
de 65 ans et plus. Cela peut être vérifié de deux façons. En 1961,
les femmes représentent 52,8 % des personnes âgées (161,6/306,3)
et en 1993 cette proportion est passée à 59,6 % (492,6/827,2).
On peut également dire qu’il y avait 90 hommes pour 100 femmes en
1961 (144,7/161,6 × 100) et que ce rapport (ou ratio
de masculinité) a baissé à 68 hommes pour 100 femmes en 1993 (334,6
/ 492, 6 × 100).
Plus l’âge avance et moins il y a d’hommes par rapport aux femmes.
D’autre part, cet écart augmente avec le temps. En 1993, il n’y a
plus, chez les gens âgés de 75 ans ou plus, que 54 hommes pour 100
femmes (contre 85 pour 100 en 1961).
Toutefois, la délimitation des classes d’âge peut perdre de sa pertinence
sur une aussi longue période. L’espérance de vie a passablement augmenté
entre 1961 et 1993, surtout pour les femmes. Qui sait si avoir 75
ans en 1961 n’« équivaut » pas à avoir 80 ans en 1993?
Pour caricaturer un peu, disons qu’il y a de plus en plus de grands-parents
par enfant (colonne 8) et qu’il y a de plus en plus de retraités par
personne active (colonne 9). Par contre, le nombre de personnes à
charge (enfants et retraités) pour chaque personne active commence
à peine à augmenter à partir de 1991 et devrait être encore inférieur
en 2036 à ce qu’il était en 1961. Cela dit, il est clair que la « charge » occasionnée par une personne âgée n’est pas la même que celle occasionnée par un enfant.
Les personnes âgées occupent une part de plus en plus importante dans
la population du Québec. Cela confirme l’intuition que nous avions
après avoir examiné les colonnes 1 à 3, à savoir que la catégorie
65 ans et plus augmente plus vite que le reste de la population. D’ailleurs,
en combinant les colonnes 7 et 3, nous sommes en mesure de calculer
la population totale pour chaque année envisagée. De plus, en combinant
les colonnes 8, 9 et 3, on peut reconstituer les effectifs des trois
principales classes d’âge.
Population totale en 1993 :
les 827,2 (milliers) de personnes âgées (colonne 3) représentent 11,5
% de la population totale (colonne 7).
827,2/Population totale = 11,5 %
Population totale = 827,2/11,5 % = 827,2/0,115 = 7 193
(milliers d’habitants)
Personnes de 14 ans ou moins (« jeunes ») en 1993 :
Il y a 58,3 personnes âgées pour 100 jeunes (ou 0,583 pour 1 si on
préfère) (colonne 8), et 827,2 (milliers) de personnes âgées.
Personnes âgées/Jeunes = 0,583
Jeunes = Personnes âgées/0,583 = 827,2/0,583 = 1 419
(milliers)
Personnes de 15 à 64 ans (« actifs ») en 1993 :
Il y a deux façons de calculer ce nombre. On peut utiliser la même
méthode que pour la classe d’âge précédente:
On a alors 827,2/0,167 = 4 953,3 (milliers) de personnes
de 15 à 64 ans.
On peut aussi y aller par soustraction :
Actifs = Population totale – Jeunes – Gens âgés = 7193 – 1 419 – 827,2 = 4947
Étant donné que tous nos chiffres sont arrondis, l’écart de quelques
milliers peut être considéré comme négligeable. Si par contre nous
avions observé un écart important, nous aurions pu en déduire soit
que nos calculs étaient faux, soit que les données du tableau étaient
fausses (la première éventualité est généralement la bonne!).
L’accroissement du nombre de personnes âgées entre 1961 et 1991 peut
s’expliquer de deux façons :
1. La cohorte de gens nés entre 1896 et 1926 est relativement grande
par rapport à la génération précédente ou à la génération actuelle. En passant, il est difficile de mettre cela sur le dos des baby-boomers.
2. L’espérance de vie augmente, puisqu’une proportion de plus en plus grande
de personnes dépasse l’âge de 65 ans).
Il serait intéressant de vérifier ces hypothèses (en obtenant des
chiffres) et d’évaluer comment ces deux facteurs influenceront la
population à l’avenir.
Même si cela n’est pas indiqué dans le tableau, sachant que les années
1945 à 1960 ont été particulièrement fécondes au Québec, on devrait
peut-être s’attendre à une forte augmentation de la classe d’âge des 65
ans et plus entre 2010 et 2025. Et comme par hasard, l’année fatidique
2015 tombe en plein milieu de cette vague. Si on estime, de plus,
que l’espérance de vie continuera d’augmenter, la progression
relative du groupe de personnes âgées devrait même de s’accélérer.
Eh oui, l’écart s’est creusé au cours des années entre hommes et femmes
(quoiqu’il tende finalement à se stabiliser). La population très
âgée est de plus en plus dominée par des femmes (et par des
veuves). Cela aura sûrement des implications sur le plan matériel,
culturel, psychologique, etc. Voilà un bon sujet d’étude.
On a beau dire, la proportion de personnes âgées plafonnera à un niveau
relativement faible. Étant donné que l’espérance de vie est d’environ
77 ans au Québec (en 1993) et qu’elle augmente très lentement, la
population de 64 ans et moins sera toujours beaucoup plus nombreuse
que celle de 65 ans et plus… à moins qu’on arrête carrément de faire
des enfants, auquel cas le problème finira par être réglé définitivement.
Si on estime (en simplifiant beaucoup) que les personnes de moins
de 15 ans et de plus de 64 ans sont à la charge des autres personnes,
on s’aperçoit que le poids de cette charge a baissé depuis 1961 (colonne
10). Ce poids commence à peine à remonter dans les années 1990 et,
en 2036, il sera encore inférieur au niveau de 1961. Au début de cette
section, nous nous inquiétions du financement des futures retraites.
La colonne 10 nous donne ici un bon éclairage. C’est finalement plus
une question d’organisation que de fardeau réel. Il n’y a donc pas
de quoi s’alarmer, pourvu que le problème soit traité honnêtement
et intelligemment.
Il n’en demeure pas moins que les personnes à charge ne sont plus
les mêmes : les personnes âgées remplacent les enfants. C’est ce qu’on
remarque clairement dans la colonne 8. Pour chaque jeune, il y a de
plus en plus de personnes âgées : 16 personnes âgées pour 100 jeunes
en 1961 et 58 en 1993. Il y a aura bientôt plus de grands-parents
que de petits enfants! Ces derniers seront particulièrement gâtés
(et peut-être mal élevés, ce qui risque de mal les préparer à leurs
responsabilités d’adultes ayant un nombre croissant de personnes à
charge).
Par curiosité, nous avons tenté d’obtenir de l’information supplémentaire.
Le tableau 6.7 montre que le Régime des rentes du Québec est justement
devenu déficitaire en 1991. Il n’y a rien d’anormal à ce que les dépenses
d’un tel régime dépassent ses revenus à certaines périodes. Après
tout, il y a des années de vaches grasses (arrivée d’une grosse vague
de gens en âge de travailler) et des années de vaches maigres (la
vague atteint l’âge de la retraite). Par contre, si le déficit devait
persister à plus long terme, il serait approprié de prendre des mesures
immédiates.
2.4. Et qu’en est-il, 20 ans plus tard?
Le texte qui précédait a été écrit en 1996. Le moment est venu de mettre nos données à jour (lignes en bleu dans le tableau 6.5b figurant ci-après). Nous constaterons d’emblée que nos prévisions de 1996 y sont largement confirmées. Il n’y a là rien d’étonnant compte tenu du sujet étudié (la démographie, phénomène hautement prévisible) et de la façon d’aborder ce sujet (les méthodes quantitatives). Nous sommes loin des scénarios catastrophiques évoqués par les politiciens de 1996.
Quelles sont les grandes lignes qui se dégagent du tableau 6.5b? Tout d’abord, le nombre de personnes âgées de 65 ans et plus a effectivement continué à progresser rapidement depuis 1991 (colonne 3). Cependant, il ne faut pas oublier que la population totale du Québec a également augmenté entre-temps. En définitive, le rapport de dépendance de ce groupe d’âge par rapport à l’ensemble de la population passe de 11 % en 1991 à 15,7 % en 2011, ce qui est substantiel, mais pas dramatique (colonne 7).
Quant au rapport « Personnes à charge/Personnes actives », qui correspond très approximativement à la colonne 10, il est resté particulièrement stable depuis 1981, et il se situe nettement en dessous de sa valeur de 1961, époque des familles nombreuses. Cependant, en 2011, le nombre de personnes âgées à charge a rejoint — et dépassé — celui des enfants à charge (observer l’écart entre la colonne 9 et la colonne 10).
Le ratio calculé à la colonne 8 confirme ce qui vient d’être dit, puisqu’il a franchi le cap des 100/100. Les enfants seront donc de plus en plus gâtés, comme nous l’avions d’ailleurs prédit. En gros, le ratio « grands-parents/petits-enfants » est passé de 1 pour 6 en 1961 à 1 pour 1 en 2011.
Comme nous l’avions entrevu en 1996, le taux d’accroissement du nombre de personnes âgées a effectivement ralenti durant les années 1990. Entre 1991 et 2001, ce taux est de (961,6 – 781,2)/781,2 = 23,1 % (contre 36,1 % pour la décennie précédente). Ce n’est qu’à l’approche de la décennie 2010 que ce taux se remet à grimper : l’effet baby-boomers commence seulement à se manifester. Il n’est en effet pas difficile de vérifier que 1945 + 65 = 2010!
Entre 1991 et 2011, un phénomène inattendu s’est produit au Québec, et dans de nombreux pays développés : l’espérance de vie des hommes a rattrapé une partie du terrain perdu par rapport à celle des femmes. En conséquence, après un long déclin, les rapports de masculinité se sont redressés pour les hommes de 55 ans et plus (colonnes 4 à 6). Les femmes d’un certain âge auront donc de meilleures chances que prévu de se trouver cavalier pour danser le tango (ou le triple swing).
EXERCICES 2
1. Qui fait les travaux à la maison?
Une enquête de Statistique Canada sur la famille et les amis indique
comment les hommes et les femmes perçoivent leur participation aux
travaux domestiques au Canada. L’enquête, qui est basée sur un échantillon
de 13 000 personnes environ, révèle que la participation des hommes
à la préparation des repas, à la vaisselle, au ménage et au lavage
est la plus élevée chez les couples non mariés, chez les jeunes, et
chez les gens les plus scolarisés.
a) Définir. D’après le texte qui précède, quelles sont la population
et les variables étudiées? Parmi ces variables, lesquelles figurent
dans le tableau 6.8 ci-dessous? Sur les 6411 hommes de l’échantillon
interrogé, 996 prétendent faire la vaisselle tout seuls et 1115 avec
leur conjointe. Vérifiez ces chiffres à partir du tableau 6.8.
b) Observer. Rédigez, sous forme de phrases, les 3 ou 4 faits saillants
qui se dégagent du tableau.
c) Analyser. Quelles hypothèses pouvez-vous faire à la lecture du
tableau 6.8? Distinguez ce qui est démontrable de ce qui est spéculatif.
d) Supplément d’information. En quoi le tableau 6.9, figurant ci-après, présente-t-il
un intérêt pour la question étudiée? Commentez-le.
3. ANALYSER UN GRAPHIQUE : LES FILLES EN PANTALON
Les années 1966 à 1968 ont marqué un tournant dans l’évolution des mentalités.
Les étudiants envahissaient les rues de Paris, les hippies californiens
se réfugiaient à la campagne et les G.I. désertaient au Canada, les
seins nus apparaissaient sur les plages de la Côte d’Azur, les jeunes
Chinois coiffaient leurs professeurs du bonnet d’âne, les parents,
nourris de Luis Mariano, Bing Crosby ou Fernand Gignac, ne comprenaient rien à la musique
de Pink Floyd. Et nous pourrions en rajouter… Ah oui, autre chose :
les filles se mirent à porter le pantalon.
3.1. Un phénomène de société
Nous allons étudier ici le port du pantalon (c’est notre variable)
des jeunes Françaises (c’est notre population) et l’évolution de
cette variable autour de 1966-1968 (les années charnières). La variable
est observée, de façon indirecte, à travers l’image fournie par deux
revues de mode parisiennes : L’enfance et la mode et Modes
et travaux. La variable port du pantalon est mesurée selon
une échelle nominale comprenant deux catégories : absence ou présence
du pantalon dans l’habillement. Les données représentent des proportions
(filles en pantalon par rapport à l’ensemble de filles) et sont exprimées
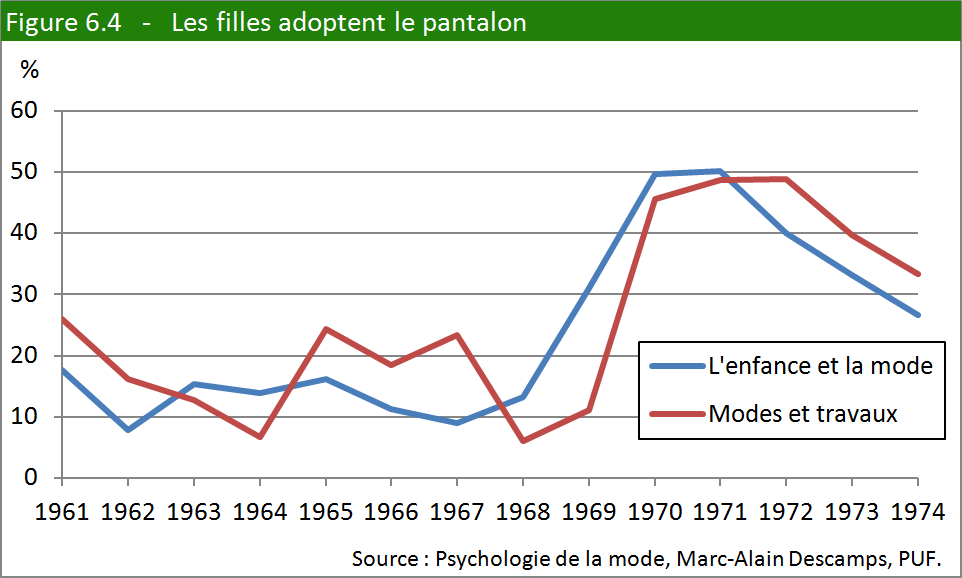
en pourcentage. La figure 6.4 illustre le résultat de l’enquête.
Avant 1969, le port du pantalon par les filles reste marginal. À
partir de 1969 (après le tournant culturel dont nous parlions plus
haut), le pantalon devient un habit féminin à part entière, qui peut
se porter aussi bien pendant les loisirs qu’au travail. On remarque
également, en dehors de ce grand virage, des fluctuations constantes :
la mode peut varier d’une année à l’autre. Les deux phénomènes (long
terme et court terme) se superposent.
On observe une très forte corrélation entre les deux courbes
(en d’autres mots, les courbes se suivent de très près). Cela renforce
l’idée que l’image projetée par les revues colle pas mal à la réalité.
Par ailleurs, on constate qu’une des courbes précède l’autre de façon
presque systématique. L’enfance et la mode a une longueur d’avance
sur Modes et travaux. Cela peut s’expliquer par le fait que
la première revue s’adresse aux gens du métier (qui sont à l’avant-garde)
alors que la seconde est destinée au grand public.
Si les revues reflètent le changement des mœurs, elles ont elles-mêmes
une influence sur la manière de s’habiller. Dans ce sens, il y a une
influence mutuelle entre le phénomène proprement dit (la façon dont
les filles veulent s’habiller) et l’image projetée dans les revues.
EXERCICES 3
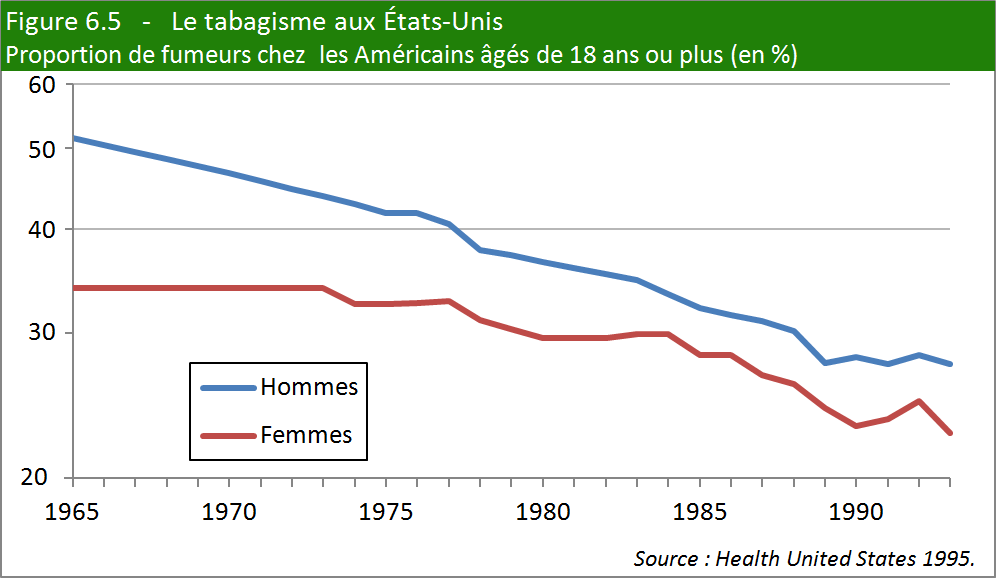
1. La cigarette en perte de vitesse
Dans les années 1960 et 1970, les amphis ressemblaient parfois à des tripots clandestins tant la fumée des cigarettes y était épaisse les jours d’examens. Une bonne moitié des hommes et un tiers des femmes s’adonnaient alors au « vice » du tabagisme. Mais le destin de la cigarette était déjà scellé, et son usage avait déjà amorcé son inexorable déclin, suite aux multiples campagnes de santé publique.
En 2011, l’enquête annuelle du CDC (organisme du gouvernement américain) évaluait la proportion de fumeurs à seulement 19 % de la population adulte.
a) Quelle est la population étudiée? Quelles sont les deux caractéristiques
de cette population (ou variables) qui nous intéressent ici?
b) Expliquez le choix de l’échelle sur l’axe vertical.
c) Commentez les courbes.
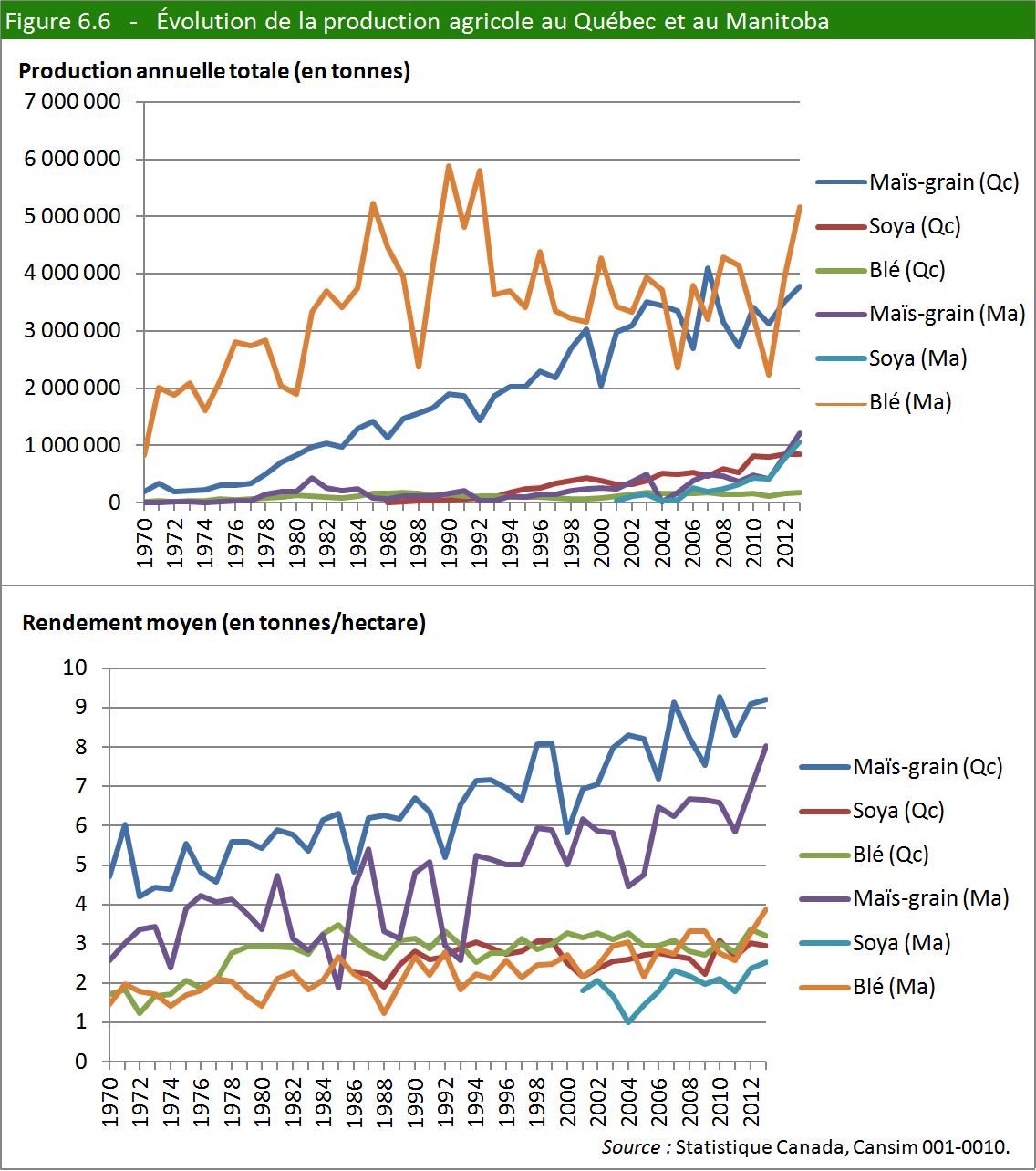
2. Un parfum d’OGM
La figure 6.6 montre l’évolution de la production et du rendement de trois grandes cultures au Québec et au Manitoba. Vous vous baserez sur la grille d’analyse
présentée au début de ce chapitre pour répondre aux questions suivantes.
Complément d’information :
Au premier semestre 2014, les prix mondiaux moyens de la tonne de maïs, de blé et de soya étaient respectivement de 211 $, 348 $ et 549 $ (source : FAO).
a) Définissez. Énoncez les éléments qui ont servi à la construction des figures. Expliquez notamment la relation entre les deux séries de courbes (production et rendement).
b) Observez.
c) Interprétez.
4. CONSTRUIRE SES PROPRES TABLEAUX
De nos jours, il est facile d’accéder à un nombre considérable de bases de données statistiques gérées par des organismes publics ou internationaux tels que la Banque mondiale, l’ONU, Eurostat, Statistique Canada, l’INSEE, etc.
Le tableau brut est la mine ou on puise l’information chiffrée.
Il faut reconnaître que bon nombre de tableaux publiés par les organismes
statistiques s’avèrent fort complexes : ils contiennent
beaucoup de variables (par exemple, le partage des travaux ménagers
selon le sexe, le niveau de scolarité, l’état matrimonial, l’âge et la langue), elles-mêmes divisées en un grand nombre de catégories (les dizaines de langues parlées dans chacune des 98 divisions de recensement du Québec). Certaines variables sont de plus affublées de noms à coucher dehors (par exemple, « taux de croissance mensuel de la consommation en dollars enchaînés de 2011 aux pondérations de 2002 convertis sur une base annuelle »). Ces tableaux « bruts » ont cependant un double mérite : ils sont souvent exhaustifs (tout est couvert) et les définitions sont précises (même si elles sont parfois longues). Ils sont la matière première, la mine d’or dans laquelle le chercheur peut puiser son information.
Les chiffres intéressants peuvent être extraits du tableau
brut et présentés dans un plus petit tableau, clair et agréable à consulter.
Les chiffres extraits d’un tableau brut peuvent être présentés dans
un nouveau tableau, facile à saisir, ou à l’intérieur d’un texte.
Dans le premier cas, seule l’information essentielle (en fonction
de la recherche) est retenue. Le tableau brut que nous avons utilisé au sujet des nationalités dans l’ex-Yougoslavie comptait 8 pages (une pour chaque république et région autonome) et
portait sur 12 nationalités différentes (qui pouvaient varier d’une
région à l’autre). Étant donné que nous nous intéressions plus particulièrement
au conflit bosniaque, nous avons réduit le tableau original à quatre
nationalités ou groupes de nationalités, et à trois républiques.
Quant aux tableaux ou aux graphiques tout faits destinés au grand public, ils possèdent un triple inconvénient pour le chercheur. Les données y sont souvent déjà transformées (dans les tableaux) ou imprécises (dans les graphiques). De plus, ces données transformées sont plus difficiles à traiter que les données brutes. Enfin, utiliser ces données déjà transformées serait faire preuve de peu d’originalité puisqu’elles sont le fruit du travail d’un autre chercheur. Mieux vaut mettre la main sur les données brutes, que l’on peut ensuite transformer et enrichir selon ses besoins.
Pour construire un tableau à partir d’une base de données, on sélectionne trois dimensions : les variables, l’époque et la zone géographique couvertes.
Si la lecture de tableaux déjà construits peut servir de source d’inspiration, la meilleure façon de procéder consiste encore à construire ses propres tableaux. Dans une première étape, le chercheur sélectionne, dans une base de données, les variables pertinentes ainsi que l’époque et la zone géographique qui l’intéressent. Dans une seconde étape, il « fait parler » les données en transformant les données brutes en rapports, moyennes, taux de variation, etc. C’est ce que nous verrons dans cette section à travers quelques exemples reliés à la criminologie.
4.1. Les gendarmes et les voleurs
Le jeu des gendarmes et des voleurs, autrefois très populaire dans les camps de vacances et les mouvements de jeunesse, est sans doute appelé à disparaître, dans un monde où les relations entre les individus se « dématérialisent » de plus en plus. L’équipement nécessaire au jeu des gendarmes et des voleurs est on ne peut plus simple sur le plan technologique : il suffit d’avoir sous la main une balle et un groupe d’enfants, que l’on divise en deux camps placés face à face. Les gendarmes doivent capturer les voleurs, en les frappant avec la balle, tandis que les voleurs cherchent à intercepter cette balle au vol et à la faire parvenir, par-dessus le camp des gendarmes, jusqu’aux voleurs déjà en prison. Ces derniers peuvent alors s’évader s’ils réussissent à faire rebondir la balle sur un gendarme. Ce jeu passionnant, qui pourrait durer une éternité, s’arrête le plus souvent quand un des joueurs portant des lunettes, qu’il soit gendarme ou voleur, reçoit la balle en pleine figure.
Où l’on voit que les règles de l’exclusivité et de l’exhaustivité sont omniprésentes dans les statistiques reliées aux sciences humaines.
Au Québec, un gendarme est une personne « responsable d’effectuer la surveillance du territoire, de répondre aux appels des citoyens, de procéder aux enquêtes de base, d’assurer le transport des prévenus, d’effectuer des activités de prévention ainsi que d’appliquer les lois et les règlements ». En 2012, 63 % des policiers permanents du Québec travaillaient à la gendarmerie, tandis que 17 % d’entre eux s’occupaient des enquêtes, et 13 % étaient affectés au soutien opérationnel (détention des suspects, identité judiciaire, pièces à conviction, renseignements criminels, liaison judiciaire, etc.). Les 7 % restants se répartissaient entre les relations communautaires et la prévention (seule catégorie où les femmes étaient majoritaires), la direction et l’administration.
Les policiers du Québec ont — à tort ou à raison — la réputation d’être grassement payés. Or, au moment de la grande réforme des fusions municipales au Québec, la question des salaires versés aux policiers provenant de municipalités différentes et regroupés au sein d’un même corps n’a pas manqué de se poser. Fallait-il aligner les salaires sur le niveau le plus élevé, sur le niveau le plus bas ou sur un niveau intermédiaire? Il ne s’agit bien sûr que d’une des multiples questions soulevées par la réforme. Pour y voir plus clair, nous avons décidé de construire un petit tableau contenant quelques données de base, propres à permettre une amorce de réflexion. Nous avons identifié six variables clés et nous avons choisi six villes du Québec (dimension zones géographiques), peu avant les fusions (dimension époque). Les résultats sont rassemblés dans le tableau 6.10, que nous vous demandons d’examiner attentivement. Nous vous demandons également de réfléchir sur le choix des six variables.
À première vue, le tableau 6.10 ne paraît pas fournir d’information extraordinaire. On y voit bien que Montréal est une grosse métropole, avec un gros budget, une grosse population et beaucoup de policiers, mais cela n’a rien d’original. Il suffirait pourtant de quelques calculs élémentaires pour que le tableau « se mette à table ». Pour défricher le terrain, nous avons donc calculé les proportions en colonnes (tableau 6.10b). Notons, avant d’aller plus loin, un petit détail important : la population de Québécois qui nous intéresse ici est celle qui est desservie par un corps de police municipal, soit 5,666 millions de personnes sur un total de 7,310 millions au 1er janvier 1999.
Le tableau 6.10b devrait se lire de la façon suivante : quelle est la proportion occupée par chaque municipalité par rapport à l’ensemble du Québec, et ce pour chacune des variables? Nous voyons d’emblée que 46,0 % de tous les policiers du Québec œuvrent à Montréal, ville dans laquelle n’habitent que 31,3 % des Québécois desservis par une police municipale. À première vue, on pourrait affirmer que Montréal compte trop de policiers. Certains pourraient même conclure hâtivement que les policiers, comme les médecins, répugnent à exercer en province. Mais n’allons pas si vite! Les policiers se trouvent principalement là où se trouvent les criminels, ou ceux jugés comme tels. Or, il est clair que les grandes villes, et les centres de ces grandes villes, constituent généralement un terrain plus intéressant pour les criminels que les banlieues-dortoirs et les villages perdus au fond de la campagne. D’ailleurs, si Montréal ne compte que 31,3 % des Québécois la nuit, il en va autrement pendant la journée, quand les banlieues-dortoirs, justement, se déversent sur la métropole. En fin de compte, il ne semble pas anormal de trouver tant de policiers à Montréal. L’ancienne ville de Hull, flanquée de ses deux banlieues, Gatineau et Aylmer, se trouve dans une position similaire, à une échelle réduite. Hull possédait d’ailleurs autrefois le surnom de « Petit Chicago ».
Le déséquilibre fiscal entre villes centrales et banlieues est un phénomène bien documenté. Étant donné qu’une partie importante des recettes municipales provient des impôts fonciers (bâtiments et terrains), il est utile de comparer la richesse foncière de Montréal (35,7 % du total québécois) à ses effectifs policiers (46,0 % du total). En d’autres termes, on pourrait considérer que le fardeau (46,0 %) de la métropole est plus considérable que ses capacités (35,7 %). Il n’est alors pas étonnant que le chiffre du budget municipal soit situé entre ces deux valeurs.
Examinons maintenant le coût du corps de police de Montréal (43,3 %) et comparons-le à l’ensemble du budget (41 %), dont ce coût fait évidemment partie : Montréal consacre une plus grande proportion de son budget à sa police que la moyenne du Québec. Si nous comparons maintenant le coût du corps de police (43,3 %) à la proportion de policiers (46 %), nous pouvons en déduire que Montréal dépense moins par tête de policier que le reste du Québec. Il est possible que les policiers de Montréal soient moins bien équipés que leurs confrères, mais il est surtout probable qu’ils sont moins bien payés.
Pour en avoir le cœur net, nous avons calculé quelques rapports, c’est-à-dire que nous avons divisé certaines variables par d’autres variables, opération à la portée du premier écolier venu, mais immensément féconde (tableau 6.10c).
Une première constatation saute aux yeux, c’est l’importance du salaire versé à un policier en 1998 (et, probablement, de nos jours). Cette année-là, alors que la rémunération moyenne d’un policier de la ville de Québec tournait autour de 73 000 $, le revenu moyen d’un Québécois atteignait à peine les 28 000 $, et le revenu médian s’établissait seulement à quelque 20 100 $ (source : Statistique Canada, Cansim 202-0402; chiffres convertis en dollars courants).
Les policiers des quatre coins du monde, qui sont généralement moins scolarisés et moins bien payés que la moyenne de la population qu’ils desservent, demeureraient surpris, voire incrédules, en prenant connaissance des salaires obtenus par leurs confrères québécois.
Le ratio Policier pour 1000 Habitants est également révélateur. Ce ratio est bien plus élevé dans les grandes villes (Montréal) et dans les centres-villes (le « Petit Chicago ») qu’en province (Rouyn-Noranda) ou en banlieue (Aylmer, Gatineau). La ville de Québec se trouve dans une position intermédiaire.
Le travail n'est pas encore terminé. Avant de conclure que les policiers sont trop nombreux à Montréal et Hull, par exemple, il faut se demander ce qui détermine la présence de policiers sur un territoire. Un des éléments à ne pas négliger est certainement le nombre de crimes commis. Le site du Ministère de la Sécurité publique du Québec contient justement d'autres données sur le sujet. On y constate que Montréal a connu 20 004 crimes avec violence en 1998, ce qui équivaut à 11,26 crimes pour 1000 habitants. C'est plus que dans l'Outaouais (7,35) et dans la ville de Québec (4,69).
Il y aurait bien d'autres commentaires à faire sur les tableaux dérivés. Il a suffi de quelques calculs très simples et surtout d'un peu de méthode pour découvrir la richesse de l'information disponible.
4.2. La base de données sur le crime aux États-Unis
Les chiffres qui nous ont permis de créer le tableau précédent provenaient d’un rapport riche en données brutes. Cette fois-ci, nous irons chercher directement les chiffres dans une base de données.
Les statistiques sur la criminalité, comme bien des statistiques reliées aux sciences humaines, sont parfois difficiles à analyser à cause de disparités dans la définition des variables. Avant de comparer les données sur les vols de véhicules, par exemple, que ce soit dans le temps et dans l’espace, il faut s’assurer que tout le monde s’entend, et s’entendait au point de départ, sur ce qu’est un véhicule. Simple, direz-vous, et pourtant… Doit-on considérer un bateau à moteur comme un véhicule? Un wagon de chemin de fer? Bon, admettons que la définition mérite d’être clarifiée, mais en ce qui concerne les homicides, la situation est nette et tranchée, n’est-ce pas?
Pourtant, seriez-vous capable de répondre sans hésiter aux questions suivantes? L’exécution d’un condamné à mort constitue-t-elle un homicide? Le policier qui descend un criminel pendant un holdup commet-il un homicide? Et qu’en est-il d’un commerçant qui tue, en état de légitime défense, le cambrioleur qui s’est introduit dans son magasin? Et le chauffard qui écrase des écoliers, pendant qu’il consulte sa page Facebook sur son téléphone? Et les victimes des attentats du 11 septembre 2001? Ont-elles été victimes d’un homicide? Le ministère de la Justice des États-Unis, par exemple, ne classera aucun des cas cités dans les homicides. Il est donc important de bien cerner les définitions des variables avant de les interpréter. Il faut aussi, avant de se livrer à des comparaisons, tenir compte du fait que certaines définitions peuvent changer d’une époque à l’autre ou d’un organisme à l’autre. D’où l’intérêt de mettre sur pied un système uniformisé, tel que fichier DUC au Canada et le fichier Uniform Crime Statistics aux États-Unis.
Le tableau 6.11 provient de ce dernier fichier. Nous avons commencé par sélectionner les variables sous forme de données brutes, puis nous avons choisi quelques États aux quatre coins de l’Union (afin de construire la figure qui accompagne ce tableau). Dans un premier temps, nous nous sommes contentés de résumer la situation dans ses grandes lignes (première partie du tableau 6.11). Comme notre étude couvre un demi-siècle, et que la population des États-Unis s’est accrue entre-temps, nous avons calculé des taux de crimes par habitant, une opération qui ne prend que quelques secondes avec un chiffrier (seconde partie du tableau 6.11).
Les infractions inscrites dans le tableau 6.11 sont regroupées en deux catégories : les crimes avec violence et les crimes contre la propriété. Comme on peut le constater d’emblée, les années 1970 à 1990 ont été marquées par une vague de la criminalité, qui semblait alors « inarrêtable ». Et pourtant, toutes les catégories de crimes se sont mises à reculer par la suite, parfois dans des proportions substantielles.
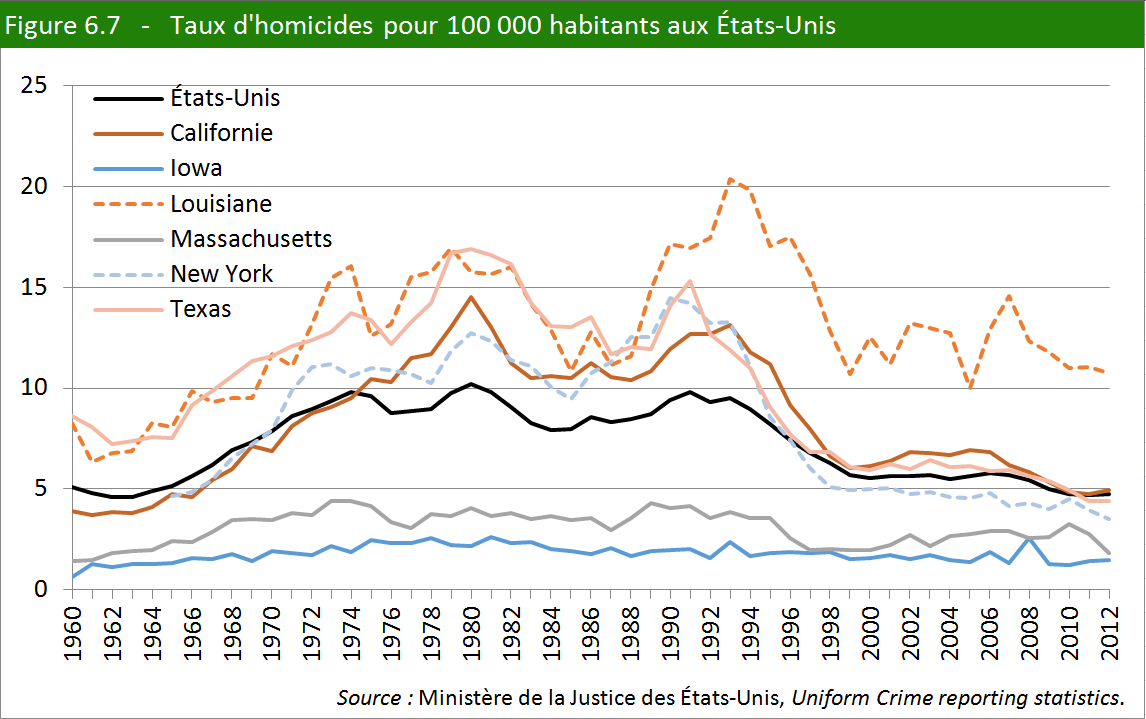
Le fichier uniformisé américain contient également des données sur les 50 États et sur des milliers de villes. Afin de nous livrer à une première étude de l’évolution de la criminalité dans le temps et dans l’espace, nous avons choisi la variable Homicides et nous avons retenu six États, mais les possibilités d’étude étaient presque infinies (figure 6.7)
La moyenne nationale est représentée par la courbe en noir sur la figure. On y voit que le taux d’homicides progresse rapidement à partir de 1964 (ère du rock), pour atteindre un sommet en 1974 (ère du disco). La situation est plus ou moins stable jusqu’au début des années 1992, où s’amorce la décrue.
On ne sera pas étonné de trouver l’Iowa, et même le Massachusetts, bien en dessous de la moyenne. Par contre, la Californie, terre des hippies, dépasse largement la moyenne américaine dans les années 1975 à 1997. L’État de New York, réputé pour ses violences à la même époque, se classe aujourd’hui au-dessous de la moyenne.
Ce n’est qu’un début, une première prise de contact. Il nous resterait à continuer notre recherche en fouillant dans cette mine d’informations que constitue une telle base de données.
4.3. Les homicides à New York
Pour comprendre la criminalité, il est important d’examiner d’autres variables que les crimes eux-mêmes. Qui sont les criminels? Qui sont les victimes? Sont-ils jeunes ou vieux, hommes ou femmes, Blancs ou Noirs, récidivistes ou néophytes? Le tableau 6.12, extrait d’un rapport du Service de police de la ville de New York, fournit justement ce type d’éclairage. Nous vous demandons, avant de poursuivre votre lecture, de bien décortiquer ce tableau en utilisant la grille de lecture habituelle, comme s’il s’agissait d’une question d’examen.
Voici maintenant un exemple des points que l’on pourrait relever en examinant ce tableau.
Autres variables (pour référence) : Population, Policiers
Proportions selon la deuxième série de variables (Race, Sexe, Âge, Casier)
Données d’une grande métropole
B. Observer
Les meurtriers sont surtout des Noirs et des Hispaniques, des hommes, des gens relativement jeunes (18 à 40 ans), des personnes avec casier judiciaire (comparer aux proportions respectives dans la population).
Les victimes sont aussi surreprésentées selon les mêmes variables, sauf pour le casier judiciaire (comparer aux proportions dans la population). On remarque quand même qu’une bonne moitié des victimes a aussi un casier judiciaire.
Les policiers sont surtout des hommes et des Blancs (toutes proportions gardées).
La plupart des meurtriers sont des Noirs, mais la plupart des Noirs ne sont pas des meurtriers (loin de là!). Idem pour les hommes, etc. Il ne faut pas oublier que les meurtriers et les victimes constituent une infime minorité de la population (il y avait environ 8 millions d’habitants dans la ville de New York en 2005).
Si les femmes commettent peu d’homicides, elles sont aussi moins souvent assassinées que les hommes.
C. Interpréter
Les meurtriers et les victimes appartiennent souvent au même milieu (Race, Sexe, Âge, Casier). Pour caricaturer, on pourrait dire, par exemple, que les voyous se tuent surtout entre eux, etc.
En ce qui concerne les effectifs policiers, on assiste peut-être à une diversification progressive. On embauche sans doute une bonne proportion de femmes et de non-Blancs, mais comme la carrière d’un policier dure plusieurs décennies, cela ne se reflète pas immédiatement dans les proportions (effet de génération).
EXERCICES 4
1. D’où provient la violence?
Le texte qui suit est adapté du rapport annuel du Département de la
santé et des services humains des États-Unis (Health United States
1995) et traite du taux de crimes violents perpétré sur des personnes
âgées de 12 ans et plus.
En 1992-93, les femmes avaient 6,6 fois plus de chances d’être
victimes d’un crime violent perpétré par leur conjoint (ou ex-conjoint)
que les hommes (9,3 crimes pour mille femmes de 12 ans et plus contre
1,4 pour mille). On compte chaque année, en moyenne, 1 008 000 crimes
de ce genre.
Les femmes ont à peu près autant de chances de subir des crimes
violents perpétrés par leurs conjoints ou d’autres parents (37 %)
que par des amis ou connaissances (40 %), et beaucoup moins de chances
d’être victimes d’inconnus. Chez les hommes, par contre, la situation
est très différente. En effet ,les crimes violents perpétrés contre
des hommes sont susceptibles de provenir de connaissances (44 % )
ou d’étrangers (49 %) plutôt que de parents (7 %).
a) Complétez le tableau suivant :
Taux de crimes violents perpétré sur des personnes âgées de 12 ans
et plus.
b) Quelles sont les deux variables que l’on retrouve dans le tableau
ci-dessus?
c) Quel est le nombre de femmes dans la population étudiée?
d) Commentez les affirmations suivantes :
La plupart des hommes commettent un crime violent contre leur conjointe (ou ex-conjointe).
Les femmes devraient se méfier de leur conjoint, les hommes devraient se méfier des inconnus et tout le monde devrait se méfier de ses amis.
Les femmes subissent plus de crimes violents que les hommes.
2. La récidive en Angleterre
Commentez le tableau 6.14 en vous servant de la grille d’analyse présentée au début de ce chapitre.
EXERCICES SUPPLÉMENTAIRES
1. Qui travaille le plus : les hommes ou les femmes?
Première partie : Tableau 6.15
a) Quelle est la population étudiée? Quelles sont les variables et
quelles sont leur échelle de mesure? Les données sont-elles brutes
ou dérivées? Quelle est leur unité de mesure? Qu’avez-vous à dire
sur les années choisies?
b) Calculez, pour chaque pays étudié, l’indice du temps de travail
pour les hommes et les femmes en prenant pour base 100 la moyenne
des 14 pays industrialisés.
c) Vérifiez les chiffres de la colonne 4.
d) Commentez le tableau 6.15.
Deuxième partie : Tableau 6.16
e) Quelle est la population étudiée? Quelles sont les variables et
quelles sont leur échelle de mesure? Les données sont-elles brutes
ou dérivées? Quelle est leur unité de mesure?
f) Commentez le tableau 6.16 (en le reliant au tableau 6.15 si nécessaire.)
2. La mort aux trousses
a) Commentez le tableau 6.17 en vous servant de la grille d’analyse présentée au début de ce chapitre.
b) Représentez les données selon le sexe et l’origine ethnique à l’aide
d’un diagramme en bâtons.
3. L’avortement au pays de Billy Graham
a) Commentez le tableau 6.18 en vous servant de la grille d’analyse
présentée au début de ce chapitre.
b) Représentez les données à l’aide d’un ou plusieurs graphiques.
4. L’endémie
a) Commentez le tableau 6.19 en vous servant de la grille d’analyse
présentée au début de ce chapitre.
b) Tracez deux courbes montrant l’évolution de l’incidence du SIDA
selon le sexe. Note : utilisez une échelle logarithmique pour l’axe
vertical.
Notes à placer dans le guide : j’essaie ici une approche originale. Si l’élève était
seulement capable d’utiliser la grille d’analyse de la page 2, son
cours de MQ aurait été hautement profitable. Par contre, l’approche
est casse-gueule : ce qu’on affirme peut souvent être contesté si on
se place sous un autre angle. Je compte sur vous pour rendre la formulation
la plus prudente possible. D’autre part, j’essaie de semer petit à
petit dans le chapitre les éléments qui permettront une bonne récolte
finale : même si ce n’est pas toujours apparent, ça devrait rester.
Note générale sur le chapitre (testament spirituel), à insérer en conclusion? : On dit
souvent qu’il est inutile, de nos jours, de se bourrer le crâne avec
un paquet de connaissances (une variante de l’adage mieux vaut une
tête bien faite que bien pleine). C’est vrai qu’il faut savoir réfléchir
et que les informations proprement dites sont souvent facilement accessibles.
Mais, on l’a vu tout au long de ce chapitre, la culture est un atout
pour analyser des tableaux : grâce à elles, on peut émettre des hypothèses
et dépister des relations. Bref, la culture combinée à la méthode
est un support essentiel à la recherche. D’ailleurs, le crâne a une
capacité d’absorption généralement très supérieure à ce qu’on pense.








 1.1. La démarche à suivre
1.1. La démarche à suivre